BERT发展沿革
四个部分
- 回顾Transformer的网络结构、和RNN、RNN的对比
- 介绍ELMo模型语境化的词嵌入,重点介绍其双向语言模型和根据具体语境生成词嵌入的原理
- 介绍三种使用Transformer作为特征提取器的网络:GPT、BERT。分别讨论其思路、原理、输入输出方式、下游任务的匹配方式,介绍他们的联系和区别
一:回顾Transformer
RNN的两个缺点:1.并行性能力差;2.捕获长期依赖的能力差
第一点:RNN之所以是RNN,能将其和其它模型区分开的最典型标志是:T时刻隐层状态的计算,依赖两个输入,一个是T时刻的句子输入单词Xt,另外一个输入,T时刻的隐层状态St还依赖T-1时刻的隐层状态S(t-1),这种序列依赖关系使得RNN无法并行计算,只能按着时间步一个单词一个单词往后走。
第二点:RNN长期依赖的根本问题是,经过许多阶段传播后的梯度倾向于消失(大部分情况)或爆炸(很少,但对优化过程影响很大)。梯度爆炸可以使用梯度修剪的方式解决。梯度消失的问题在引进LSTM和GRU之后也得到了解决,然而LSTM或者GRU都没有解决RNN无法并行计算的局限性。新的特征提取器Transformer能够同时解决这两个问题。
Self attention会让当前输入单词和句子中任意单词发生关系,然后集成到一个embedding向量里,简单来说就是每个单词都会产生三个向量——query、key、value,当前单词的query向量和其他单词的key向量进行内积操作,并且进行softmax归一化之后会得到当前单词和其他单词的注意力打分,然后使用注意力打分对所有的单词的值向量做加权求和。Transformer是用位置函数来进行位置编码的。Self attention层的输出会传递到前馈(feed-forward)神经网络中,每个位置的单词对应的前馈神经网络都完全一样,不是共享参数的而是各自独立的。前馈神经网络的输出就是对于特定单词想要得到的最终的词嵌入。
二:语境化的词嵌入ELMo
《ELMO:Deep contextualized word representations》是NAACL 2018的最佳论文,全称为Embedding from Language Models,它解决了以往使用RNN做为特征提取器的Word Embedding网络的一个没有解决的问题:语义多样性的问题,比如一个单词“bank”“有多种含义,取决于它的上下文是什么。ELMO的本质思想是:先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
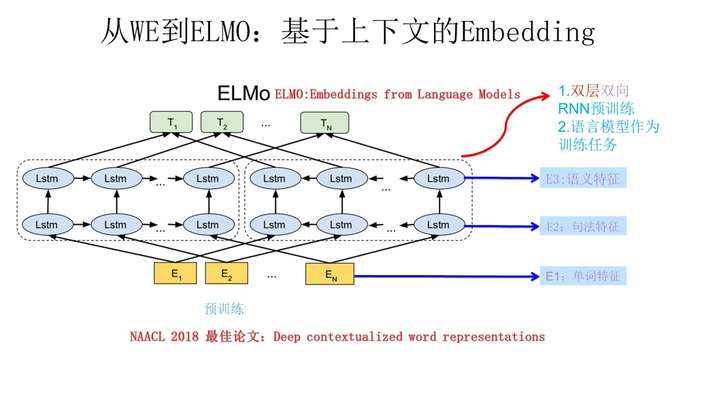
具体的实现原理:它的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词 的上下文去正确预测单词
,
之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外
的上文Context-before;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after;句子中每个单词都能得到对应的三个Embedding:最底层是单词的Word Embedding,往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
总结:ELMo使用了双向语言建模的方式使得词嵌入能够获取上下文的信息;ELMo根据具体语境下将单词的三个Embedding融合的方式解决多语义的问题。不足之处:BiLSTM的特征提取能力要显著低于Transformer。
三:GPT
GPT是“Generative Pre-Training”的简称,从名字看其含义是指的生成式的预训练。GPT也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。上图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:首先,特征抽取器不是用的RNN,而是用的Transformer;其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,ELMO在做语言模型预训练的时候,预测单词 同时使用了上文和下文,而GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。
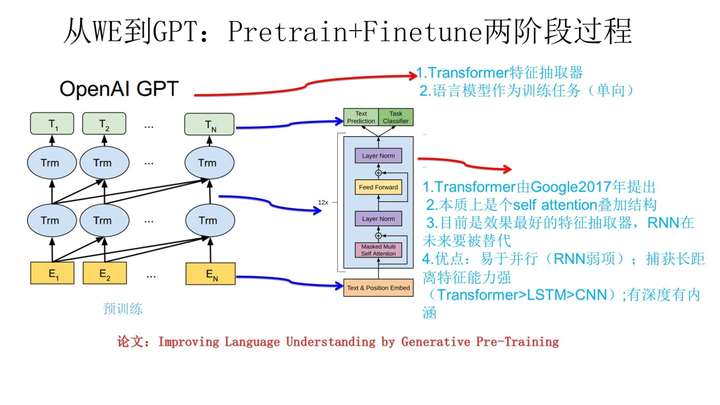
总结:GPT在BERT之前使用Transformer+两阶段训练的方式获取word Embedding,这种做法已经成为了NLP预训练模型的标准方式,所以GPT的贡献是具有开创性的。但是因为没有使用双向语言模型使得其效果很快被BERT超越,从事后看,BERT本质上也就是比GPT多使用了双向语言模型。
四:BERT
BERT=Transformer+双向语言建模预训练+下游任务Fine-tunning
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,当然另外一点是语言模型的数据规模要比GPT大。
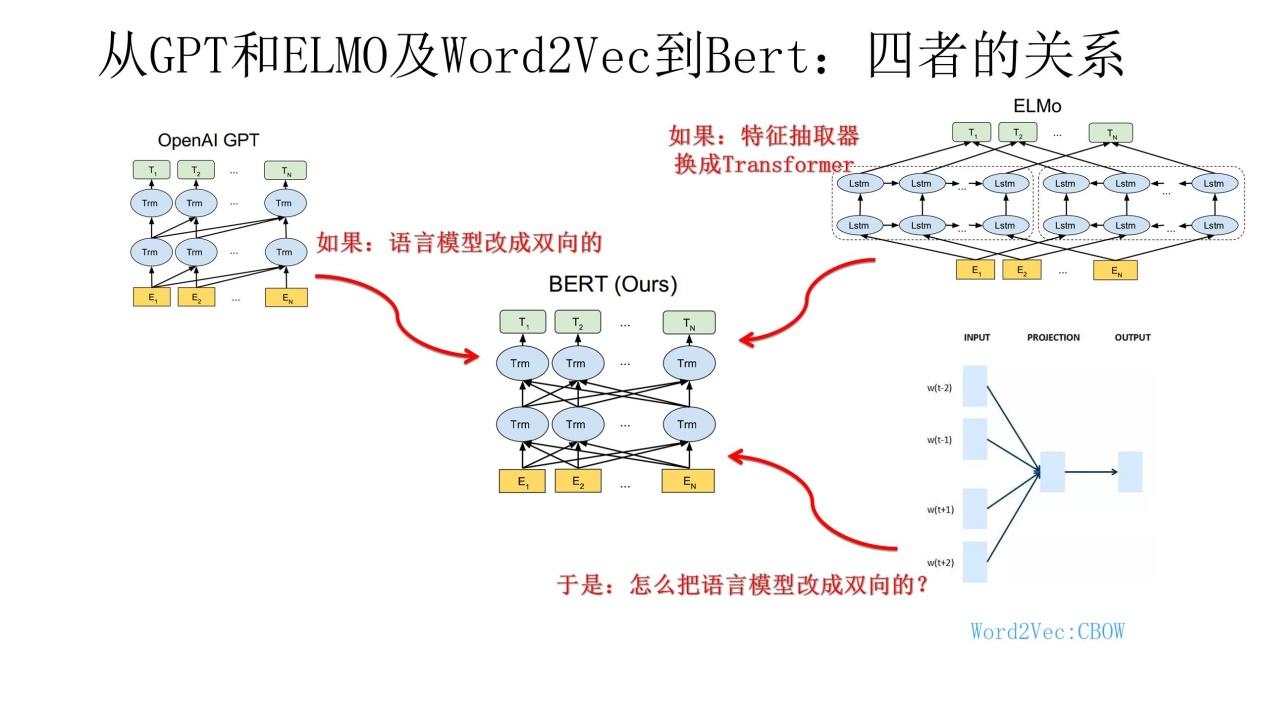
第一阶段的预训练
BERT 的创新点在于它将双向 Transformer 用于语言模型,没有使用传统的从左到右或从右到左的语言模型来预训练 BERT,而是使用两个新型无监督预测任务。
任务 #1:Masked LM
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:
- 在 encoder 的输出上添加一个分类层
- 用嵌入矩阵乘以输出向量,将其转换为词汇的维度
- 用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。

任务 #2:下一句预测
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。 在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
- 在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
- 将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上。
- 给每个 token 添加一个位置 embedding,来表示它在序列中的位置。
为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
- 整个输入序列输入给 Transformer 模型
- 用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量
- 用 softmax 计算 IsNextSequence 的概率
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
第二阶段微调Fine-tuning
BERT 可以用于各种NLP任务,只需在核心模型中添加一个层,例如:
- 在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层
- 在问答任务(例如SQUAD v1.1)中,问答系统需要接收有关文本序列的 question,并且需要在序列中标记 answer。 可以使用 BERT 学习两个标记 answer 开始和结尾的向量来训练Q&A模型。
- 在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。

- 句子关系类任务,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。
- 对于分类问题,与GPT一样,只需要增加起始和终结符号,输出部分和句子关系判断任务类似改造;
- 对于序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。
- 生成类任务,尽管Bert论文没有提,最简单的是直接在单个Transformer结构上加装隐层产生输出,更复杂一点就是使用encoder-decoder结构,编码器和解码器都是用预训练的词嵌入进行初始化。