论文:Image Inspired Poetry Generation in XiaoIce解读
论文内容
这篇论文介绍了微软小冰从一张图片生成一首现代诗的过程模型。简单来说,这个过程就是给定一个图像,首先从图像中提取几个表示对象和感知到的情感的关键字,然后根据这些关键词与人类诗歌的关联,将它们扩展到相关的新的关键词,接着每个关键词作为每行诗的核心,使用双向语言模型逐步向左右拓展生成整句。这个过程模仿人类由景生情创造诗歌的过程。设计的网络能够很大程度的保证句子之间的流畅性、整体性和与图片的匹配性;使用关键字扩展的机制使得生成的诗歌具有多样性和想象力。
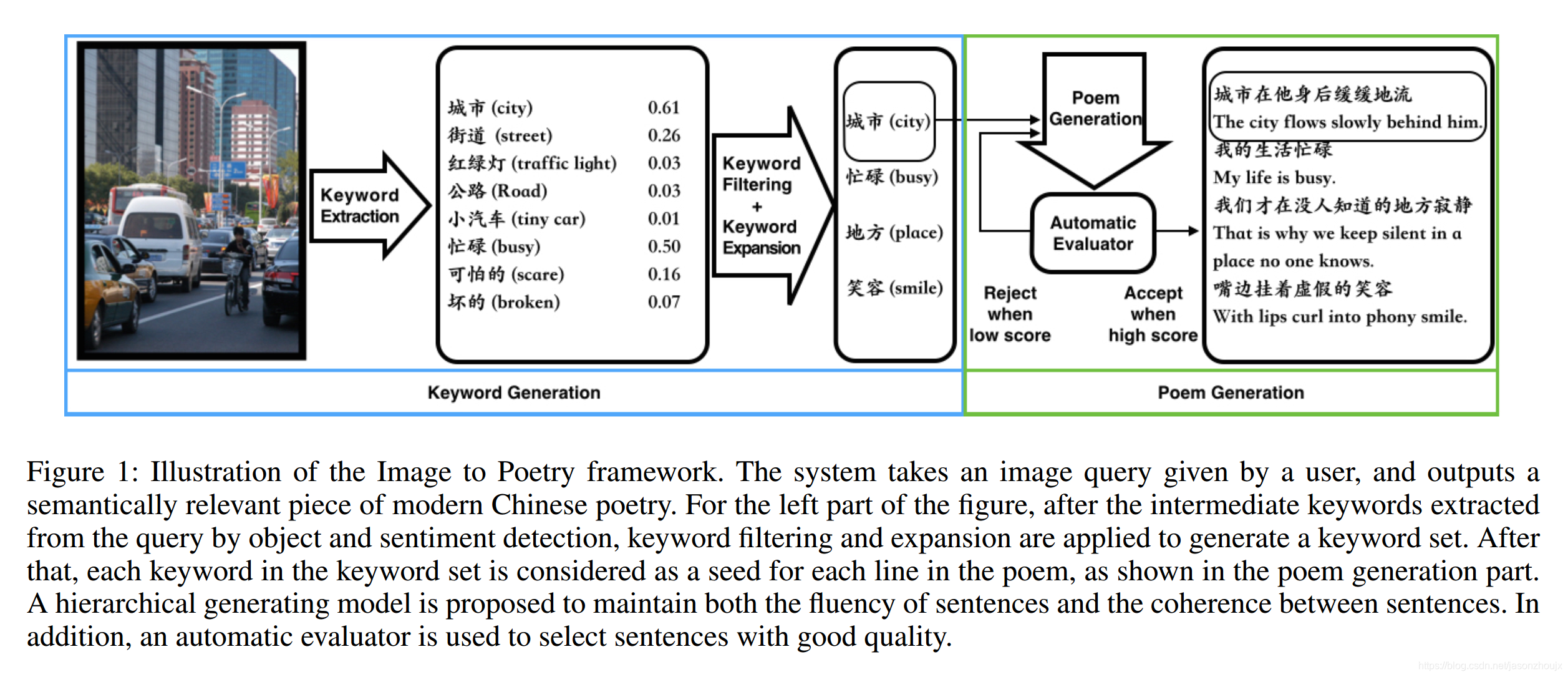
模型简介
生成现代诗比生成古代诗难度更大,因为现代诗的题材限制少,可发挥的空间更大,对想象力和创造力的要求更高。由图片出发生成现代诗的是一个有趣的任务,不同人看一幅画的感受不同,而且对图+诗的感受也是不同。以往许多诗歌创作的方法主要是给定关键字,生成包含或者关键字相关的句子,拼接起来。从图片进行诗歌生成的优点:图片包含丰富的信息,因此发挥想象力的空间更多;对图片的解读因人而异,因此由图片生成的诗歌给人的惊喜或者印象往往更加深刻;对于用户来说,上传一张自己感兴趣的图片远比思考关键词要来的简单。首先从图片中解析出实体和情感词组成关键字集合;然后对关键字集合进行过滤和扩充;最后每一个关键字都被作为一行诗的seed,使用双向的文本生成方法生成整行诗;一个层次网络能够检测出没有通过词间和句子之间流畅度检验的诗句,删除并且重新生成直到通过检验。
模型细节
问题定义
把图片记为$query Q$,目标是生成现代诗$P=(l_1, l_2, … ,l_N)$,$l_i$表示第i行诗,N是最诗歌的行数。对图片进行目标和情感检测,得到若干个关键字,然后进行关键字扩展得到一个关键字的集合$K=(k_1, k_2, …, k_N)$,一共由N关键字。对N个关键字分别进行诗句生成,检测未通过词、句流畅性的诗句,重新生成。
关键词生成
分别使用两个CNN检测图像中的目标和情感,这两个CNN结构相同但是参数不同。检测目标的CNN输出名词关键字,检测情感倾向的CNN输出形容词关键字。两个CNN网络在ImageNet上进行预训练并且在相应的下游任务上做fine-tune。论文中使用的CNN网络是Google-Net。
关键字的扩展
从图片生成的关键词的选择也是一个值得研究的问题。低可信度的关键词会有损诗句和图像的管理度,低频的关键字会造成生成的诗句质量低下。最好的方法就是选取那些高可信度且与训练集关联度高的关键字,这样做的同时又会出现关键词不足的问题,这时候就需要继进行关键字扩展。论文提出即使有效的关键字数量多于N的情况,关键字扩展也是必要的,这么做能够让诗词创作跳出直接观察到的内容,从某种程度上进行联想。论文对比了三种关键字扩展的方法。
- 不进行关键字扩展,如果有效关键字少于N,没有的关键字的诗句使用前l句的句子编码信息生成新句子。
- 使用训练集中高频的词汇进行扩充,论文中使用的是“life”、“time”和“place”。
- 高共现词汇:比如与“city”和“palce”、“child”、“heart”和“land”,这些词汇。使用高共现词能够在保证前后主题一致性的前提下获得的更好的话题扩展。
诗句生成
诗句生成过程使用语言模型来预测下一个单词$w_i$,为了让关键字出现在句子中的任意位置,论文使用递归生成的方法.具体的方法是训练一个反向的语言模型,用<sos>和<eos>分别表示句子的起始符号和结束符号,句子使用关键字k_j做初始化,在<sos>和<eos>均出现了之后停止句子的生成。交替使用正向和逆向的语言模型生成句子下一个左边和有右边的词汇,直至到达<sos>或者<eos>。

增加诗句间的约束
使用双向语言模型递归生成诗句能够保证词间的流畅性,为了保证句子之间的连贯性,在生成第$l$句诗的过程中,论文模型对前$l-1$句诗句做句子编码作为当前句生成过程的参数。论文还实现了另一种思路:只使用前一句的编码信息来约束当前诗句的生成。诗句生成使用的sentence level LSTM网络和诗句间添加约束的poem level LSTM网络的均包括3层LSTM layer,每一层包含1024个LSTM单元。

流畅性检查
生成诗歌还应该有能够在相同的关键词的情况下生成多样的结果的能力,所以模型使用top n best 的集束搜索。这样做带来的后果就是句子内容的流畅性和一致性有所牺牲。为了解决这个问题,论文对词和句的连续性进行了检验,词方面使用n-gram和skip n-gram来判断词组的正确性和两个词的语义连续性;在语法层面,我们利用词性标注语料库训练了一个基于lstm的语言模型,并将其应用于词性标注候选句的生成概率计算。丢弃没有达到标准的句子,接着重新生成。
实验设置
为了得到不同部件最优的组合方式,论文使用了贪心搜索策略,每一步都选出当前最优的组合方法,下一步再在当前结构上增加新的组件。实验分为两个部分:
- 关注不同的新词生成方法。论文提出的双向递归生成新词的方法大幅度占优;在此基础上,加入前l句信息的poemlstm的效果明显优于基于前句信息的preline。
- 关注关键词提取和扩展的质量。质量从生成关键字的相关性、创造性方面由人工进行打分,选择高共现相关方法进行关键词扩展的方法获得最高的评分。

实验结果

Baseline选择的是Image2caption和CTRIP,Image2Captain的任务是进行图片标题生成,CTRIP是一个古诗创作的模型,同样可以通过观察图像生成诗歌。评价方法:同时展示三种模型生成的内容,由人工评委进行打分,区间1-5;指标为:相关性、流畅性、想象力、动人性和给人的印象程度。结果:Image2Caption在相关性上占优,CTRIP和论文模型在其他方面大幅领先Image2Caption,论文模型在imaginative、touching和impressive上效果最好,CTRIP在流畅性上得分最高。
