解决的问题
Transformer的自注意力机制可以让长距离的单词直接联系,可以很容易地学习到句子之间的长距离依赖。但是在将Transformer应用在语言模型时,核心的问题在于如何将任意长度的context编码成固定长度的上下文变量。
普遍的做法是将整个语料库划分成较短的片段,在每个片段上训练模型。但是这么做很有几个问题:
- 最大可能依赖长度不会超过片段的长度
- 语料库按照固定长度而不是按照语义或者句子的分界划分进行分片,导致分片之间无法共享信息。这样情况下训练的语言模型会丢失一部分上下文信息,导致收敛速度和性能不符合预期。论文把这个问题成为上下文碎片问题。
贡献
- 在Transformer的基础上提出segment-level recurrence mechanism、新的位置编码模式两种方法使得Transformer-XL能够在不破坏时间一致性的情况下,学习固定长度之外依赖关系并且解决上下文碎片问题
结果
- 学习依赖的范围比RNN(LSTM)高出80%,比Transformer高出450%,
- evaluation过程速度比Transformer提高1800倍。
- 在5个语言模型数据集上取得SOAT成绩。
Recurrent mechanism机制
前一个分片的隐藏状态被保存下来作为计算下一个分片隐藏状态的扩展输入。这种方法能够在计算当前分片隐藏状态的时候使用到上文的信息,进而可以有效的避免上下文碎片并且增加依赖的长度。具体来说,前一个分片第n-1层的隐藏状态被保存下来,与当前分片的第n-1层的隐藏状态一起作用生成当前分片第n层的隐藏状态。这种“循环”利用上个分片的隐藏状态的方法能够有效加长期依赖的范围。

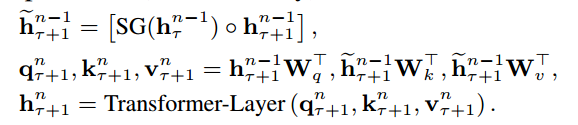
其中,下标$\tau+1和\tau$分别表示分片的编号,上标$n和n-1$表示当前计算的隐藏状态在模型中的层数,$q、k、v$分别表示计算注意力需要的查询(query)、键(key)和值(value)向量,$W$表示模型的参数矩阵。首先第$\tau$个分片第n-1层的隐藏状态$h_{\tau}^{n-1}$被保留下来,做停止更新梯度的操作之后和第$\tau + 1$个分片第n-1层的隐藏状态$h_{\tau+1}^{n-1}$做拼接得到融合了上文信息的新状态$\tilde{h}{\tau + 1}^{n-1}$,新状态被用来计算key和value向量,query向量则使用原始的隐藏状态$h{\tau+1}^{n-1}$计算。最后三个向量作为Transformer的输入计算第$\tau+1$分片n层的隐藏状态$h_{\tau+1}^{n}$。
相对位置编码(Relative Position Encoding)
从上面介绍的Recurrent机制中,我们知道当前分片的隐藏状态融合了前一个分片的信息,问题在于不同的分片的隐藏状态计算过程中使用到的初始输入的位置编码是相同的。这样模型无法根据位置编码区别不同分片中相同位置的输入单词。
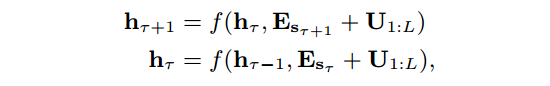
解决的办法是在每一层的隐藏状态计算时都加入相对位置编码。实际上,位置编码的作用是在计算注意力的时候提供时序的线索以组合分片中不同单词的信息,在相对位置编码的设定下,正弦编码矩阵$R$的每一行$R_i$表示相对位置差值为$i$时的相对位置编码。在注意力计算过程中使用相对位置编码,使得当前分片的查询向量$q_{\tau}$可以却分不同分片的相同位置的输入$x_{\tau,j}$和$x_{\tau -1, j}$。
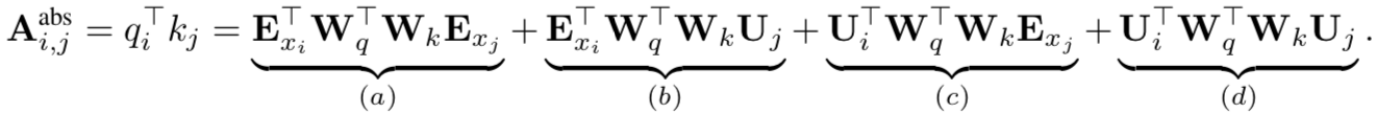
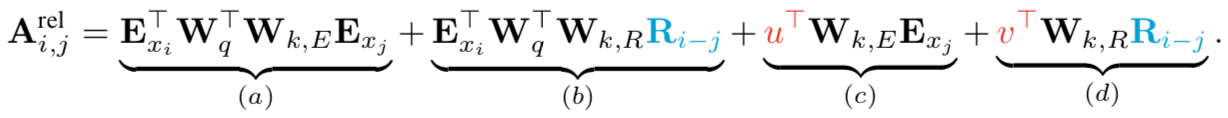 上图是transformer的一个注意力头使用绝对位置编码的注意力得分你的公式,可以拆分为四个部分。使用相对位置编码替换绝对位置编码分为三步,第一步将(b)、(d)两项末尾的绝对位置编码$U_j$替换成相对位置编码<u$U_{i-j}$,矩阵R是一个正弦编码矩阵,没有科学系的参数;第二步引入可训练的参数$u$代替(c)项的$U_i^TW_q^T$,对于任何的query位置,query向量都是一样的,也就是对不同单词的注意力倾向是相同的,同理(d)像用另一个可学习参数$v$代替;第三步,分离两个权重矩阵$W_{k,E}$和$W_{k,R}$,分别产生基于内容的key向量和基于位置的key向量。
上图是transformer的一个注意力头使用绝对位置编码的注意力得分你的公式,可以拆分为四个部分。使用相对位置编码替换绝对位置编码分为三步,第一步将(b)、(d)两项末尾的绝对位置编码$U_j$替换成相对位置编码<u$U_{i-j}$,矩阵R是一个正弦编码矩阵,没有科学系的参数;第二步引入可训练的参数$u$代替(c)项的$U_i^TW_q^T$,对于任何的query位置,query向量都是一样的,也就是对不同单词的注意力倾向是相同的,同理(d)像用另一个可学习参数$v$代替;第三步,分离两个权重矩阵$W_{k,E}$和$W_{k,R}$,分别产生基于内容的key向量和基于位置的key向量。
Attention head的计算过程
 整个计算过程其实就是将上面两个部分连在一起,首先时候分段重用机制融合之前分段信息计算得到查询、键、值向量,然后使用相对位置编码替换绝对位置编码计算注意力得分,最后经过前向网络得到当前分段的新的隐藏状态,输出给下一层的Transformer模块。
整个计算过程其实就是将上面两个部分连在一起,首先时候分段重用机制融合之前分段信息计算得到查询、键、值向量,然后使用相对位置编码替换绝对位置编码计算注意力得分,最后经过前向网络得到当前分段的新的隐藏状态,输出给下一层的Transformer模块。
Evaluation速度巨大提高
评估的时候,Transformer每次预测一个新词都需要将其前L个词作为一个分片,以保证每次预测都能使用到最长的上文的信息。但是这种预测方式需要很大的计算力。Recurrent机制能够极大程度的加速了evaluation的过程,因为保留了前一个分片的隐藏状态,而不是每次预测新词都从头开始计算,从而达到了加速的效果。
实验结果
Transformer-XL在五个数据集上语言模型的数据集上取得了SOAT成绩,包括character-level的WikiText-103、enwiki8、text8和One Billion Word四个数据集和word-level的Penn Treebank数据集。
WikiText-103数据集包含28K篇文章的103M个字符,平均每篇文章包含3.6K个字符。这个数据集可以有效的评估模型处理长期依赖的能力。
enwik8包含了100MB未处理的Wikipedia的文本。与enwiki8相似,text8同样包含了100MB的Wikipedia文本,区别在于移除了26个字母和空格以外的其他字符。
One Billion Word数据集,顾名思义包含有10亿个单词,但是该数据集将所有的句子的顺序进行打乱,因而没有保留句子与句子之间的长期依赖。但是transformer-XL依然在这个数据集上超过传统Transormer,说明transformer-XL在处理短句子时的泛化能力。
Penn Treebank只包含1M个字符,作者认为在该数据集上取得SOAT结果说明transformer-XL对于小数据集也具有良好的泛化能力。