Welcome to Henry's Blog!
这里记录着我的NLP学习之路-
自然语言处理的是个发展趋势
转载自:https://blog.csdn.net/cf2suds8x8f0v/article/details/78588562
概要:哈尔滨工业大学刘挺教授在第三届中国人工智能大会上对自然语言处理的发展趋势做了一次精彩的归纳。
哈尔滨工业大学刘挺教授在第三届中国人工智能大会上对自然语言处理的发展趋势做了一次精彩的归纳。
趋势 1:语义表示——从符号表示到分布表示

自然语言处理一直以来都是比较抽象的,都是直接用词汇和符号来表达概念。但是使用符号存在一个问题,比如两个词,它们的词性相近但词形不匹配,计算机内部就会认为它们是两个词。举个例子,荷兰和苏格兰这两个国家名,如果我们在一个语义的空间里,用词汇与词汇组合的方法,把它表示为连续、低维、稠密的向量的话,就可以计算不同层次的语言单元之间的相似度。这种方法同时也可以被神经网络直接使用,是这个领域的一个重要的变化。
从词汇间的组合,到短语、句子,一直到篇章,现在有很多人在做这个事,这和以前的思路是完全不一样的。
有了这种方法之后,再用深度学习,就带来了一个很大的转变。原来我们认为自然语言处理要分成几个层次,但是就句法分析来说,它是人为定义的层次,那它是不是一定必要的?这里应该打一个问号。

实际工作中,我们面临着一个课题——信息抽取。我之前和一个单位合作,初衷是我做句法分析,然后他们在我的基础上做信息抽取,相互配合,后来他们发表了一篇论文,与初衷是相悖的,它证明了没有句法分析,也可以直接做端到端的直接的实体关系抽取,这很震撼,不是说现在句法分析没用了,而是我们认为句法分析是人为定义的层次,在端到端的数据量非常充分,可以直接进行信息抽取的时候,那么不用句法分析,也能达到类似的效果。当端到端的数据不充分时,才需要人为划分层次。
趋势 2:学习模式——从浅层学习到深度学习

浅层到深层的学习模式中,浅层是分步骤走,可能每一步都用了深度学习的方法,实际上各个步骤是串接起来的。直接的深度学习是一步到位的端到端,在这个过程中,我们确实可以看到一些人为贡献的知识,包括该分几层,每层的表示形式,一些规则等,但我们所谓的知识在深度学习里所占的比重确实减小了,主要体现在对深度学习网络结构的调整。
趋势 3:NLP 平台化——从封闭走向开放

以前我们搞研究的,都不是很愿意分享自己的成果,像程序或是数据,现在这些资料彻底开放了,无论是学校还是大企业,都更多地提供平台。NLP 领域提供的开放平台越来越多,它的门槛也越来越降低。
语音和语言其实有很大的差别,我认识的好几位国内外的进入 NLP 的学者,他们发现 NLP 很复杂,因为像语音识别和语音合成等只有有限的问题,而且这些问题定义非常清晰。但到了自然语言,要处理的问题变得纷繁复杂,尤其是 NLP 和其他的领域还会有所结合,所以问题非常琐碎。
趋势 4:语言知识——从人工构建到自动构建

AlphaGo 告诉我们,没有围棋高手介入他的开发过程, 到 AlphaGo 最后的版本,它已经不怎么需要看棋谱了。所以 AlphaGo 在学习和使用过程中都有可能会超出人的想像,因为它并不是简单地跟人学习。

美国有一家文艺复兴公司,它做金融领域的预测,但是这个公司不招金融领域的人,只是招计算机、物理、数学领域的人。这就给了我们一个启发,计算机不是跟人的顶级高手学,而是用自己已有的算法,去直接解决问题。
但是在自然语言处理领域,还是要有大量的显性知识的,但是构造知识的方式也在产生变化。比如,现在我们开始用自动的方法,自动地去发现词汇与词汇之间的关系,像毛细血管一样渗透到各个方面。
趋势 5:对话机器人——从通用到场景化

最近出现了各种图灵测试的翻版,就是做知识抢答赛来验证人工智能,从产学研应用上来讲就是对话机器人,非常有趣味性和实用价值。
这块的趋势在哪里?我们知道,从 Siri 刚出来,国内就开始做语音助手了,后来语音助手很快下了马,因为它可以听得到但是听不懂,导致后面的服务跟不上。后来国内把难度降低成了聊天,你不是调戏 Siri 吗,我就做小冰就跟你聊。但是难度降低了,实用性却跟不上来,所以在用户的留存率上,还是要打个问号。
现在更多的做法和场景结合,降低难度,然后做任务执行,即希望做特定场景时的有用的人机对话。在做人机对话的过程中,大家热情一轮比一轮高涨,但是随后大家发现,很多问题是由于自然语言的理解没有到位,才难以产生真正的突破。
趋势 6:文本理解与推理——从浅层分析向深度理解迈进

Google 等都已经推出了这样的测试机——以阅读理解作为一个深入探索自然语言理解的平台。就是说,给计算机一篇文章,让它去理解,然后人问计算机各种问题,看计算机是否能回答,这样做是很有难度的,因为答案就在这文章里面,人会很刁钻地问计算机。所以说阅读理解是现在竞争的一个很重要的点。
趋势 7:文本情感分析——从事实性文本到情感文本

多年以前,很多人都在做新闻领域的事实性文本,而如今,搞情感文本分析的似乎更受群众欢迎,这一块这在商业和政府舆情上也都有很好地应用。
趋势 8:社会媒体处理——从传统媒体到社交媒体

相应的,在社会媒体处理上,从传统媒体到社交媒体的过渡,情感的影响是一方面,大家还会用社交媒体做电影票房的预测,做股票的预测等等。
但是从长远的角度看,社会、人文等的学科与计算机学科的结合是历史性的。比如,在文学、历史学等学科中,有相当一部分新锐学者对本门学科的计算机的大数据非常关心,这两者在碰撞,未来的前景是无限的,而自然语言处理是其中重要的、基础性的技术。
趋势 9:文本生成——从规范文本到自由文本

文本生成这两年很火,从生成古诗词到生成新闻报道到再到写作文。这方面的研究价值是很大的,它的趋势是从生成规范性的文本到生成自由文本。比如,我们可以从数据库里面生成一个可以模板化的体育报道,这个模板是很规范的。然后我们可以再向自由文本过渡,比如写作文。
趋势 10:NLP + 行业——与领域深度结合,为行业创造价值

最后是谈与企业的合作。现在像银行、电器、医药、司法、教育、金融等的各个领域对 NLP 的需求都非常多。
我预测 NLP 首先是会在信息准备的充分的,并且服务方式本身就是知识和信息的领域产生突破。还比如司法领域,它的服务本身也有信息,它就会首先使用 NLP。NLP 最主要将会用在以下四个领域,医疗、金融、教育和司法。
-
华为李航-NLP有个基本问题,深度学习4个做的很好
对于自然语言理解,有两种定义。第一种是计算机能够将所说的语言映射到计算机内部表示;另一种是基于行为的,你说了一句话,计算机做出了相应行为,就认为计算机理解了自然语言。后者的定义,更广为采用。
为什么自然语言理解很难?其本质原因是语言是一种复杂的现象。自然语言有 5 个重要特点,使得计算机实现自然语言处理很困难:
- 语言是不完全有规律的,规律是错综复杂的。有一定的规律,也有很多例外。因为语言是经过上万年的时间发明的,这一过程类似于建立维基百科。因此,一定会出现功能冗余、逻辑不一致等现象。但是语言依旧有一定的规律,若不遵循一定的规范,交流会比较困难;
- 语言是可以组合的。语言的重要特点是能够将词语组合起来形成句子,能够组成复杂的语言表达;
- 语言是一个开放的集合。我们可以任意地发明创造一些新的表达。比如,微信中 “潜水” 的表达就是一种比喻。一旦形成之后,大家都会使用,形成固定说法。语言本质的发明创造就是通过比喻扩展出来的;
- 语言需要联系到实践知识;
-
语言的使用要基于环境。在人与人之间的互动中被使用。如果在外语的语言环境里去学习外语,人们就会学习得非常快,理解得非常深。
这些现象都说明,在计算机里去实现与人一样的语言使用能力是一件非常具有挑战性的事情。首先,语言的不完全规律性和组合性,就意味着如果在目前的计算机上去实现,会产生组合爆炸;还有,如果需要语言做比喻,去联系到实践环境,就意味着要做全局的、穷举的计算。如果通过现代计算机来做,非常复杂,几乎不太可能。所以,如果想让计算机像人一样使用语言,原理上需要完全不同的、与人脑更接近的计算机体系架构。
其本质原因是,目前在计算机上去实现东西一定需要数学模型。换句话说,计算机能够做的事情要通过数学形式化。但是,到目前为止,语言的使用还不清楚是否能够用数学模型去刻画。人工智能的终极挑战就是自然语言理解。现实当中,不能因为自然语言理解非常困难就放弃。我们还是希望能够使计算机越来越智能化,能够部分使用语言。因此,就形成了所谓自然语言处理这一领域。我们叫自然语言处理,而不是自然语言理解,因为真正的理解是太难了。
自然语言处理做的第一件事情就是把问题简化。比如,知识问答中,问姚明身高是多少?朋友告诉你是 2 米 26。这是人与人之间的知识问答。那么,这其中有哪些步骤呢?首先是听,然后去理解问题,然后去做一定的推理,然后再去做信息检索,最后判断怎么去做回答,整个过程相当复杂。我们现在做自然语言处理时,也做这种知识问答,包括有名的 IBM 的 Watson,其整个步骤也是简化了自然语言处理的过程。一般而言,就是这几个步骤,先分析一下问句,接着去检索相关的知识或者信息,然后产生答案。
目前,所有的自然语言处理的问题都可以分类成为五大统计自然语言处理的方法或者模型,即分类、匹配、翻译、结构预测,马尔可夫决策过程。各种各样的自然语言处理的应用,都可以模型化为这五大基本问题,基本能够涵盖自然语言处理相当一部分或者大部分的技术。主要采用统计机器学习的方法来解决。第一是分类,就是你给我一个字符串,我给你一个标签,这个字符串可以是一个文本,一句话或者其他的自然语言单元;其次是匹配,两个字符串,两句话或者两段文章去做一个匹配,判断这两个字符串的相关度是多少;第三就是翻译,即更广义的翻译或者转换,把一个字符串转换成另外一个字符串;第四是结构预测,即找到字符串里面的一定结构;第五是马可夫决策过程,在处理一些事情的时候有很多状态,基于现在的状态,来决定采取什么样的行动,然后去判断下一个状态。我们也可以采用这样的模型,去刻画自然语言处理的一些任务。
分类主要有文本分类和情感分类,匹配主要有搜索、问题回答、对话(主要是单轮对话);翻译主要有机器翻译,语音识别,手写识别,单轮对话;结构预测主要有专门识别,词性标注,句法分析,文本的语义分析;马可夫决策过程可以用于多轮对话。我们可以看到,自然语言处理里面有很多任务,在现实中我们已经开始使用最基本这五种最基本的模型它都去可以去刻画的。
语言处理,在一定程度上需要考虑技术上界和性能下界的关系。现在的自然语言处理,最本质是用数据驱动的方法去模拟人,通过人工智能闭环去逼近人的语言使用能力。但是,这种技术并没有真正实现人的语言理解机制。可能会有这样的情况,这个技术的准确率(绿线)画了一个上界。比如,语音识别的上届是 95%,我们希望不断把这个技术做好,比如通过人工智能闭环,更好的深度学习方法,从而使得上界不断提高。但是,不可能一下子达到百分之百对,或者达到完全与人一样的水平。每个应用,对于下界的要求是不一样的。比如,在葡萄牙问路,对方也不会英语,我也不会葡萄牙语,交流非常困难,在这种环境下我其实就是听懂几个单词,让机器翻译给我翻译几个单词就行了,对性能的要求其实是比较低的,不需要去翻译一大段话。我们可以看到,不同的应用,用户对使用性能的要求不同,如果下界达到这个水平,用户就用了。再比如互联网搜索中排序第一的准确率不高,60% 多 - 70% 多,大家往往觉得,互联网搜索引擎已经达到要求了。当然因为搜索的时候,通过排序展示给用户多个结果,用户可以去逐个去看,一定程度上解决一些问题,这时候对性能要求下界相对就比较低。如果,现在的技术上届达到了用户要求的下界,就能够使用。所以,哪些自然语言处理的技术未来能够起飞,能够真正实用化,就可以通过这种关系来看。还是要看具体的应用的场景。在一些特定场景下,准确率达到 99% 都不行。我们相信,自然语言处理的技术会不断提高,但是是不是都能够达到我们每一个应用要求的性能的下界,就不好说了,要看未来的发展了。这是自然语言处理技术整个发展情况。
下面,给大家一起看一下我们自然语言处理领域里面都有哪些技术,有代表性的技术都大概达到什么样的水平,都是什么样的一些基础。假设大家对深度学习有一定的了解,如果这方面的知识还不够也没关系,过后你可以去再去看书看论文,去了解一些相关的技术情况。
刚才,我介绍到站在一个很抽象的角度来看,自然语言处理就是五个问题。如果用各种方法包括深度学习把这五个问题做好了,就能够把自然语言做得很好。现实当中,我们就是通过深度学习,达到自然语言处理技术比较好的水平。
首先,问答系统有很多,包括 IBM 的 Watson 也是一个问答系统,有大量的知识或者信息放在知识库。典型的办法就是把问答用 FAQ 索引起来,与搜索引擎相似,如果来了一个新问题,有一大堆已经索引好的 FAQ,然后去做一个检索(字符上的匹配),之后逐个去做匹配,判断问句与回答的匹配如何。往往匹配的模型有多个,再去将候补做一个排序,把最有可能的答案排在前面,往往就取第一个作为答案返回给用户。
这里面牵扯到几个技术,我们在在线的时候要做匹配和排序,现在最先进的技术都是用机器学习,用深度学习技术。就是把问句和回答的可能的候选,用向量来表示,问句的每一个单词都可以用向量来表示。每一个词的语义都可以用一个实数值向量赖表示,问句和候补都是实数值向量的序列。然后,用一个二维的卷积神经网络来判断两句话在语义上是不是相关,候选是否是很好的答案。通过二维卷积神经网络,可以判断两句话里面哪一些词语、词组是可以相互对应,最后可以做一个判断这两句话是不是相关的。整个模型的学习通过大量的数据、句对,去训练。如果卷积神经网络的参数学好,就可以判断任何给定的两句话是不是能够构成一轮问答。
这样的模型不仅仅可以用到文本问答(知识问答)上,也可以用到图像检索上面。给大家演示一个 demo。
这种模型,可以跨模态的把文本和图片联系起来。在深度学习技术出现之前的话,这件事情是不可能的。因为他们是不同的模态。一个是符号表示的信息,一个是像素表示的信息,那么我们可以用深度学习的模型去做这种跨模态的匹配。比如,左边有一个卷积神经网络,他能够抽出左边图片的语意表示,表示成一个向量;右边也是一个卷积神经网络,能够把一段文字的内容抽取出来,表示成为一个向量,还有一个网络判断这两个向量在语义上是否能够匹配。这个模型可以通过大量的数据去训练。假设每一个照片有 3 到 5 个人给出描述。我们用大量这样的数据就可以学这样的神经网络,神经网络可以帮助我们,就是说任何给定的一句话,要去查找一个图片的内容,它就可以在这个图片库里帮你去匹配到最相关的图片,给你返回来。这个技术也是在深度学习出现之前应用的,因为我们不知道怎样把图片和文字匹配到一起。有了深度学习技术,我们可以做这样的事情。
自然语言对话是用另外一种技术,用生成式的模型去做自然语言对话。大量的聊天系统是这么做的,输入一句话,里面准备了大量的 FAQ,搜索到一个最相关的回答,反馈给你。这叫做基于检索的自然语言问答系统。
我们这里看到是一种产生式,经过大量数据训练之后,输入一句话系统自动的产生一个回复,理论上产生出无穷多的不同的回复。下面先看一个实际系统的录像。
这个系统,我们在微博上爬了四百万的微博数据,微博数据可以看作是一种简单的单轮对话。我们用 400 万数据训练了这样一个系统能够去自动产生对话。(系统演示)
理论上它可以回答任何你输入的对话。用 400 万的微博数据就可以训练这样一个模型。系统产生一句话的比例是 96%,真正形成一个有意义的单轮对话的比例是 76% 左右。这个系统的一大特点是,可以回答没有见过的一句话。
第二个特点是能够记住训练数据。发现深度网络有一个共同的特点就是能够记住训练数据,同时也有去泛化的能力,能针对未知的新见到的东西去自动组织出一句话,并返回给你。这种能力很令人惊叹,是否实用并不清楚。在一个很固定的场景里,比如话务中心,如果话务员跟客户之间的交互都是简单的重复,大量的类似数据可以构建一个产生自动的回复系统,而且跟人的回复非常接近。
大家如果熟悉深度学习的话,刚才说自然语言处理有很多问题都是翻译的问题,即把一个文字的字符翻译成另外一个文字字符,那么单轮对话的产生也可以看成是机器翻译。序列对序列学习,sequenceto sequence learning,可以用到这种单轮对话中。每个单词其实是用一个实数值向量表示,就是编码,之后用实数值向量分解成一个回复的一句,叫做解码。通过这种编码、解码这两个过程的话,我们把原始的数据转化成中间表示,再把中间表示,转换成为应该回复的话,可以产生对话系统。
谷歌的神经机器翻译系统是一个非常强大的系统,需要很多训练数据和强大计算资源。这个 seqto seq 模型有八层的编码器和八层的解码器,整个网络非常深。它还用了各种这个新的技术,比如注意力技术,并行处理技术,还有模型分割和数据分割等。目前,翻译的准确率已经超过了传统的统计机器翻译。
下面,再看一下未来自然语言处理技术发展的前景和趋势。刚才我们看到技术上界和用户对于性能要求的下界,碰到一起就看到技术的使用化。那么,就预测一下未来自然语言处理技术的发展。目前,几个最基本的应用,包括语音识别,就是一个序列对序列学习的问题,就是翻译的问题,目前准确率是 95% 左右,那么已经比较实用了。单轮对话往往可以变成一个分类问题,或者结构预测问题,就是通过手写一些规则或者建一些分类器,可以做的比较准。很多手机上应用或者是语音助手像 siri,就是用这样的技术;多轮对话还很不成熟,准确率还远远达不到一般期待的要求,只有在特定场景下能做的比较好。单轮问答已经开始实用化,准确率一般来百分之七十八十,自动问答系统没有超过 80% 的这个准确率的情况。去年,我有一个报告就讲鲁棒的自动问答或者知识问答,并不要求准确率是百分之百。单轮自动问答会马上越来越实用化,因为我们看到很多成功的例子包括 Alexa 往往都是用单轮对话技术来做的。文本的机器翻译水平在不断提高,深度学习在不断进步,越来越接近人的专业水平,但只是在一些特定场景下。完全去替代人,还是不太可能。人的语言理解是一个非常复杂的过程,序列对序列实际上是一种近似,现在这种技术能够去无穷尽的逼近人,但是本质上还是跟人的做法不一样的。即使是这样,准确率可以达到百分之七八十。在某些场景下,用户对性能要求并不是特别高。
总而言之,语音识别、机器翻译已经起飞,大家现在开始慢慢在用,但是真正对话的翻译还很困难,还有很长的路要走,但是也说不定能够做得很好。并不是说序列对序列就没有问题需要解决了,还有细致的问题。一个典型的问题就是长尾现象。不常用的单词、语音识别、翻译还是做得不是很好。比如用中文语音输入,人名、地名这种专有名词识别率一下就下降,特殊的专业术语识也不好,讲中文中间夹杂一些英文单词也是一种长尾现象。因为现在机器学习的方法是基于统计的,原则上就是看到数据里面的规律,掌握数据的规律。需要看到甚至多次重复看到一些东西,才能够掌握这些规律。这块相信有很多技术能帮助解决一些问题,使得机器翻译或语音识别技术不断提高,但是完全彻底的解决还是比较困难,因为这是这种方法带来的一个局限性。
单轮的问答,特别是场景驱动的单轮的问答,可能慢慢会开始使用。但是多轮对话技术还是比较难。马尔可夫决策过程实际上是还是个统计学习模型,本质特点就是需要有大量的数据去学习。其实我们人在做多轮对话的时候,并不需要重复才能掌握这种天生能力。这些是否能够用马尔科夫决策过程去模拟或者近似还不是很清楚。还有一个重要的问题就是多轮对话的数据不够,不能够很好地去学习这样的模型,去研究这些问题。即使是特定任务,多轮对话还比较困难,如果是任务不特定,比如聊天机器人就更难了,我们都不知道该怎么去做,马尔科夫决策过程都用不上。现实当中的一些聊天机器人就是用单轮技术堆起来,但是形成不了一个很自然合理的多轮对话,变成大家用起来觉得很奇怪的东西。总结起来就是多轮对话,在任务驱动的简单场景,有了更多的数据,我们是有可能做的越来越好。
给今天的讲座大概做一个总结,自然语言理解很难,自然语言处理现在用数据驱动的办法去做,有五个最基本的问题,即分类、匹配、翻译、结构预测和马尔可夫决策过程。在具体的问题上,有了数据就可以跑 AI 的闭环,就可以不断提高系统的性能、算法的能力。深度学习在我刚说的五个大任务里的前四个都能做得很好,特别是运用 seq toseq 的翻译和语音识别。单论对话也能做的越来越好,但是多轮对话需要去研究和解决。
自然语言概括的那部分其实我也写过一些文章,大家感兴趣的话也可以去看一看,网上也能搜得到,然后还有就是我们相关的工作论文,包括谷歌的工作论文,我在这里列出来了。
最后,欢迎大家加入我们的实验室。方向有语音、语言处理、推荐搜索、大数据分析、智能通讯网络、计算机视觉、物联网、智能城市、智能终端。谢谢大家。
李航 VS 雷鸣 对话部分
雷鸣:特别感谢李老师精彩的讲座。今天这个讲座基本上对自然语言的整个发展能解决什么问题做了一个综述,而且对于技术、挑战和未来展望讲得特别全面,以致于我想到一个问题,后面就已经在回答了,今天讲得非常全面,非常仔细。我们想跟李航老师再探讨一下应用方面,我们知道华为的诺亚方舟做了很多计算语言方面的工作,能大概讲一下在落地方面做了哪些产品,大概现在处在一个什么水平上吗?
李航:好的。我们在语音、语言这方面做了两个应用,一个是机器翻译,一个是自然语言对话。机器翻译在我们公司内已经广泛使用,没有推到外面做产品。因为华为是一个非常国际化的公司,大概有不止三、四万的非中国籍员工,所以中翻英,英翻中在公司内使用,我们的技术都应用在里面。还有云对话的应用场景就是手机。
雷鸣:助手。
李航:对,助手。手机的东西一直在做,现在不太方便说,欢迎大家到我们实验室访问,我们可以做进一步介绍。
雷鸣:李航老师也组织一次北大、清华、中科院的同学一起去参观,关起门来比较好说。提到对话这块很有意思,比较早的商用系统是 Siri, 包括在《生活大爆炸》里也看到调笑 Siri 的场景,最后发现也就是大家稍微玩一玩,后面就没有后面了。我们发现比较实用化的对话系统反而是亚马逊做的 Echo,客观地讲亚马逊在自然语言的技术积累以前没有见太多,比起苹果、谷歌、甚至百度都不那么强,那为什么它能先做出来一个特别落地化的东西?它走了一个什么样的路径?对我们技术落地有什么启发?能大概解释一下吗?
李航:好。据我所知道的情况,亚马逊收购了几个公司,问答那部分是英国的剑桥做的,他们已经做了多年的这种问答,它们做得好的地方在于细节处理得非常好。也就是说问答的技术是亚马逊买来的。还有麦克阵列那些好像也不是自己开发的,细节我不是很清楚。但是自动问答我很清楚,就是收购的技术。
问答,或者说是广义的对话,刚才笼统地讲,有三类不同的技术,他们之间其实并不是包含和被包含的关系,是相互独立的。一种是分类或者结构预测,直观来说就是人手写规则,Siri 或者以前典型的场景都是基于这种技术做的。写好规则,这句话匹配上了,或者叫分类,分类对了,就去做了。还有一种技术就是问答,这种基于搜索、检索技术的比较多,有索引、排序这套东西,这你也是专家。再有就是多轮对话,比如说强化学习。这三套技术其实相互都比较独立。
说到匹配的话,模板、规则,或者说分类比较适合命令型的东西,未来就是家居各种场景,包括手机的命令,这种场景里面准确率相对也比较高,因为相对场景比较局限,能够达到百分之八、九十的识别准确率,甚至更高一些,应该是能够比较多地实用化。我们看到未来这是一个很好的场景。还有就是你刚才讲到 Alexa 的问答已经做得很好,这也是我觉得未来能够去实用化的一块,因为 Alexa 已经迈出非常好的一步了。它可以不断地跑人工智能闭环,收集更多的数据去把这个东西做得越来越好,就是内容不够填内容。如果是说 “理解” 用户的问法,还是用我们这种匹配、排序的技术,能看到哪个地方有问题就可以去改进,能够不断地把对话、问答这种东西做得越来越好。这两块我觉得都是未来能够起飞,能够用起来的技术。
多轮对话,刚才也说到,就是还需要很多研究了。数据也不够,大家都没有数据,是这样的一个状况。
雷鸣:可不可以理解为,他们虽然没什么积累,但是买的公司还挺厉害的。
李航:对,还挺厉害的。
雷鸣:有很牛的技术。第二点来讲,它进入到家庭场景里面,这个场景本身的限制导致说这个问题被降维了。
李航:对,就是实现做得比较好。
雷鸣:Siri 相当于一个开放式的,所以难度比较大一些。做到大家都满意就比较难一些,因为技术并不是一步到位的,选择技术能解决的问题去解决,解决实际问题然后再落地是更现实的事,可能会比较有挑战。谷歌成立很久,其实为全球培养了大量的科学家,出来了无数的创业公司,但是到现在好像还没有一个商业化成功的案例,所以他们走得有点儿太远了。
李航:是的。
雷鸣:刚才李航老师讲了好几次关于人类的语言,就是自然语言这一块它的复杂度是蛮高的,可能超过了用数学公式表达,或者是用概率就能搞定的。现在由于大量的数据积累,包括深度学习,使得在简单的语言问题上我们看到一种可解性。面对将来复杂的语言问题,我们现在能不能看到一个路径将来能够走到那一天?比如说这个路径大概是什么样子?现在在学术界,包括您这里有什么看法?比如说刚才讲这个多轮对话是个非常有挑战的问题,今天我们看到确实挺难的,多轮开放就更难了。但是有没有一种方向性的东西使得我们能够往那个方向走?
李航:这个问题问得很好,大家现在往往就是对人工智能过于乐观,包括自然语言处理也是一样,整个人工智能也是这样,还需要很多努力,还有漫长的路要走。面向未来的话,我们诺亚方舟实验室做研究一个大的方向就是怎么把知识和深度学习这样的技术结合起来。换一个角度就是说把符号处理 symbolic processing 和神经处理 neural processing 结合起来,这能够帮助我们做很多事。不一定能解决你说的多轮对话的问题,但是能帮助我们人类做很多事情。
你们可以这样想,计算机第一个是计算比咱们人类厉害,第二就是存储比人厉害。现在有互联网,各种信息库、知识库,但是我们觉得用起来还不是很方便,很多问题不是简单地通过搜索引擎就能去做。一个关于 symbolic neural processing 就是神经符号处理的想法就是,给计算机大量的文本,都是用符号表示的知识和信息,让它不加休息地去读,然后结合深度学习的技术,让它学到更好的知识表示、语义表示。对于每个人来说就是一个智能助手,帮助你去记忆各种东西,包括具体的信息,包括知识,这对我们人的能力是一种更大的延伸。不一定是多轮,但是是简单的多轮。实际上是把我们整个知识、信息的获取、检索的这样一个大的任务都解决,对我们每个人的能力是一种延伸。不光是知识,信息也可以融合起来。比如说,上次我和雷老师见面谈了什么都可以很快地导出来。这就扩大了我整个的能力,记忆的能力,存储的能力。这方面我们看到一些可能性,不好说是不是能突破,这也是自然语言知识问答的延伸,目前还做不到,做得不好,我们正在往这个方向一步步走,这是我们希望有突破的。
今年 1 月份我们去蒙特利尔访问了深度学习三大牛人之一 Bengio,请教了他关于 neuralsymbolic processing 的看法,他也是比较认可。他认可这种意义的结合,但是在一般意义上,如在深度网络里加一些 symbol,他认为是不对的。刚才说的这种意义上的结合他觉得还是有道理的,当然还有很多未知的问题,很多挑战,但是是值得进一步去探索的。我们现实中也开始在做一些研究。
雷鸣:这个回答大家去品味一下,技术发展无止境,有些时候一些特定的技术方式能解决一些特定的问题,但有时候也不是完全通用的。今天深度学习虽然很火,但是现在也有些反思,它是不是能解决所有问题。不同的学者有不同的想法,大家要用自己的智慧去理解。
刚才李航老师讲到 symbolic neural processing,从产业里我们有时候会从工程看问题。比如说自然语言这方面,第一是从语音到文字,如语音识别,现在专门有人做这个,做得还不错。第二就是从文字到语义,就是我知道你在说什么。第三层就是 response,就是我知道你在说什么,我再给你一个有效的反馈。从这三层来看,第一层做得还不错,第二层就是机器看到一段文字,到底理解没理解这个是否有个定义,咱们待会儿探讨一下。第三层就是来一个问题给一个正确的反馈,这和问题的理解层面纠缠有多深?因为我看到现在都是把问题和答案对着训,把内涵加进去了。就比如说对牛弹琴有两种,一个是它根本听不懂你谈的东西,第二是听懂了但它不知道是什么意思。聊天也一样,对方说的每一个字我都懂,但是合起来不懂,或者说合起来说的我也都懂,但是不知道怎么回答。从学术上看,刚才讲到语音分开得比较清楚,就是语义理解和回答这两块的研究我看一体化比较严重,从长远来看应该是分开还是合并的?每一块有什么挑战?
李航:这个问题问得非常好。这就牵扯到自然语言处理的本质的问题。我个人观点,说到人工智能、自然语言处理还有很长的路要走的意思就在这儿。一个就是要任务驱动才能去做,撇开任务单纯讲语义这是很难的,包括回答。深度学习的好处就是我们现在能做端到端的学习,输入、输出,里面都是黑箱,学习就好了。不好的地方就是中间发生什么都不知道。你刚才说对应人的语义,这个都不知道。深度学习肯定就有局限了。理想就是能够把人的支持加进来帮助语义的理解。刚才讲到 Bengio 也觉得这个事情不太好做,当然他也不一定绝对就对,但是这块是挺有挑战的,有太多不知道的事情了。
雷鸣:有一次我看到你提到谷歌的翻译,他们做的其实还是很牛的。以前我们都是端对端,英汉、汉英训练一个模型,诸如此类很多模型。但是谷歌是训练了个挺通用的模型,比如说英中对译训好了,中法对译训好了,然后英法之间就直接可以开始对译了。
李航:那是另外的一些工作,但是都是相通的。我今天介绍的不是太一样。业内有这样技术,有这样的研究。
雷鸣:这个我觉得挺有意思的,核心是我们没有训过英法之间的对译。这也就意味着,某种意义上来说,我们感觉机器在深度网络学习的时候对人类的语言做了一个内隐的表达。它在英中、中英、英法学习中间有个层面学会了英语的表达,然后就直接对上了。是不是说它找到了人类语言的某种内在表达方法?但是因为刚才说到的深度学习的特性导致我们读不出来,可不可以这样理解?
李航:我同意你的观点。就是这是做了一种表达。比如人做翻译其实也是一个很复杂的过程。你们有没有观察过专业的同声翻译,我只是从旁观察或跟他们交流,发现他们其实不思考的,他们已经形成了一种模式训练。不是所有外语好的人都能做同声翻译的,需要做一些特殊的训练。我的解释是他们其实是学了各种模式,但是他们很快,并不需要理解。他们就是有一种中间表示,很快就能转换成目标语言,我们现在的深度学习多少有点儿像那样一个机制,就是大量数据去训练。但往往我们一般人做翻译事实上是有语言的理解的,同声翻译至少局部就是一个模式。所以我同意你的观点,就是让中法、中英这些都一起训练,可能针对某些语言映射到内部有一些表示,对于语义的理解是比较 universal 的,就可以通用。
雷鸣:您刚才提到语义这一块您想说一下。
李航:对。有一篇文章是《迎接自然语言处理新时代》里面有写这个事情。你刚才谈到语音,语音只是人大脑里的一个模块,语言处理是整个大脑都会参与的,所以说语言本身就是很复杂。语音就是一个模块,所以语音处理不是一个人工智能完全的问题。语言处理是需要很多语言的知识模块参与在一起去做,而且大家可能也知道,脑区里面负责语言的部分都不止一个,多个脑区同时参与做这个事情。
雷鸣:占的面积也挺大的。
李航:对。现在大脑很多事情我们不知道。我们最早知道的一个有意思的事情是什么呢,就是给猴子的 premotor cortex 插上电极,发现有一个脑细胞在猴子自己吃香蕉和看到别人吃香蕉时都会有反应,说明在猴子的前运动域有一个脑细胞对应吃香蕉这个概念。然后人去做核磁共振这个实验,发现也是跟运动相关,比如说张开嘴或想象张开嘴,通过核磁共振去看脑区的反应的地方是一样的。让人去做某个动作和想象做某个动作是在大脑前运动皮质,而不是小脑,小脑是指挥你怎么样去运动,但是对应的大脑皮质有些运动的概念。有个假说就是有一个或多个脑细胞就是对应那个动作的概念。
现在有个我比较喜欢的假说,就是其实我们大脑皮质的一些细胞对应一些概念。比如喝水,看到人喝水,这个脑细胞可能就被激活,读小说读到有人在喝水,这个脑细胞也会被激活。所以说为什么读小说大家有身临其境的感觉,就是说视觉刺激和文字刺激都能刺激那个脑细胞,那一个或多个脑细胞就是对应这个概念。每个人理解语言的时候肯定是不完全一样的,因为每个人经验不一样。脑细胞被激活的过程是,成长过程中你的经历形成那些脑细胞激活的机制,相关的一些概念容易被联想出来,每个人容易联想的事情肯定是不一样的。但大家肯定有一些共性,如果差太多就没法交流了。脑细胞表示的概念还有很多共性的东西,使得我们能够做交流,能共同去做事情。既有共性,又有个性。
整个理解语言的过程就是激活相关的所有脑细胞对应的概念,把它们联系起来,然后还有自身体验的这种联系,这就是每个人对语言的理解。这个过程其实是非常复杂的。有人说意识占我们大脑处理的 2%,有个人极端的说法是下意识占 98%,就是说对语言的理解和处理实际上是在下意识中进行的,整个过程非常复杂,而且是并行处理,牵扯到到里面的很多个模块,达到了所谓对语言的理解。说话、写和看到的东西都是 symbol,都是非常表层的东西。它背后牵扯到,产生或理解这个文字符号时背后的大部分东西都是在我们大脑里无意识的情况下进行的。这是非常复杂的,怎么去把它发掘出来,到底是怎么一回事儿,非常复杂。本身大脑规模又非常大,大家知道大脑有 10 的 11 次方的个神经元,15 次方的连接。
雷鸣:对,1000 亿的这么一个复杂的系统。
李航:对,就是这么一个复杂的系统,这么一个复杂的现象,我们要去再现这种理解的过程,从现在的技术来说是非常困难了。
雷鸣:其实对大脑的研究现在在相当初级的阶段,我也关注比较久,基本上就跟你说的一样,大概到脑细胞激活这个研究,只能对特别简单的一些低等生物做一做,对人还是做一些脑区分化和相关性的一些研究。
其实深度学习的发展跟对大脑的理解有很大关系。现在不知道还算不算,一段时间以前我记得还有两个派别,一个态度是说尽量要了解清楚大脑的结构,然后进入模拟大脑的过程,模拟得足够快,就会产生通用智能。还有一个就是说,造飞机不需要造出一个会扇翅膀的。我们大概了解清楚了,用机器的告诉照样可以超过。我们不知道哪个是最终答案,但我觉得研究大脑的结构肯定能够促进人工智能的发展,人工智能的发展反过来也会促进我们对大脑的研究,这是相辅相成的。
如果在座的大家对人工智能感兴趣的,还是比较建议大家去读一读神经生物学。神经的结构、大脑这些看一看会对大家很有帮助。大脑是怎么做决策的,意识、直觉、痛苦,行动这些都会讲到,挺有意思的。比如说我说一句话,不要想一个红色的苹果,你们脑子里有没有一个红色的苹果?所以劝人时不要说,你不要哭了,你别难受了,这完全起不到任何作用,因为他听到的就是难受,就是哭。小小地讲一下大脑很有意思的这一点。
雷鸣:自然语言研究里还有很大一部分,叫做知识库,就是尝试建立一个知识表达。现在知识库的研究在整个 NLP 中处于一个什么位置呢?在以深度学习方法为主流的 NLP 中,还会有它的位置吗?
李航:这是很热的一个领域,研究很多。但是这方面我看的东西不是特别多。我更关心的是结合应用。这跟你刚才提的另外一个问题相关,就是怎么样去定义知识。如果不是应用驱动的,而是纯粹去定义知识的话,到目前为止我们看到的结果都不理想。你建完了很大的知识库,也不知道该怎么用。就是说,知识表示是不是合理,如果没有一个明确的应用,就很难判断。目前对人类语言机制的理解并不清楚。应用驱动、数据驱动是我们的主要想法,知识库建设也应该是这样。大家现在在朝这个方向走,有一个大趋势。我不知道你们注意到没有,大概 4、5 年前知识图谱这个概念就很火。很多公司都在做。那时有些很有野心的项目,比如要做巨大的知识图谱等等。这些项目后来基本都停顿了。大家发现,真正要做这种通用的知识库还是很难的。就我了解的范围内的共识,是说其实可以做一些领域知识库,比如说医疗知识库。又比如说我们在华为做了通讯领域知识库。这是更现实的。在应用里面去使用,能够解决实际的问题。
这是知识库方面的一个趋势,或者说是动向吧。应该结合到实际的应用里面。你建了知识库无外乎就是希望大家去使用这些知识库。我们希望,如果 Neural Symbolic Processing 这种新的技术有突破的话,如果知识的获取和检索能够解决的话,大家就能够更好地去使用知识库。这是最基本最重要的应用。从这一角度来看,我们没有特别关注知识库本身,而还是以应用驱动、数据驱动,看神经和符号的结合。
雷鸣:李航老师从科研界出来,在产业界摸爬滚了一段时间,观点是典型的以应用为驱动。用得着的项目,我们就放进去用;用不着的,就先放在那里,先慢慢研究。我也是这样的人。(笑)
另外,刚才李航老师也说到,有一些我们认为很高大上的技术,现在作为通用的解决方案可能还非常困难。可能由于运算能力不够、数据不够,甚至是模型的复杂度不够,或是理论模型还不能支撑。这时我们可以在一个小领域里先应用它,降难度,限场景,先把它用起来,有时发现,在 vertical 的小领域里面,它还是挺好用的。
好,下面我们看一下同学、观众在我们的微信群、公众号和网上直播中提出的问题。一个同学问,主流的聊天机器人,比如小冰、小娜等等,现在主要是用什么技术实现现在的结果的?
李航:不说具体的系统,聊天的技术一般来说主要还是基于检索的。产生式的对话系统真正到了实用阶段的我们还没有看到,或者说看到的不多。因为有很多风险。有一个风险是,它说的话可能都是对的,但是它说的事实是错的。比如你问它,姚明身高多少?它说,1 米 2。这种时候你还能判断出它是错的。但有时候无法判断,就很码放了。深度学习不知道怎么去控制这个系统。不知道在什么时候能让它说出准确的答案。
我们现在其实也做了一些研究,还都是比较偏基础的一些东西,到使用阶段还有一些距离。即使聊天机器人,里面也还不是一些实用的技术,基本上都是基于检索的多轮对话的技术。简单说就是上下文对齐、指代消歧,这样的事情也能局部地做一做,但缺少一个整体的多轮对话的模型。我刚才也说到,现在任务驱动的时候,有马尔科夫决策过程,但如果是闲聊,是 open 的,那么都没有一个很好的数学模型去刻画这一过程。所以这还是非常难的一个事情。
雷鸣:下一个问题。为什么国际会议上都是用英文的数据集,大家比来比去,为什么中文的 NLP 研究相对就少一些?
李航:没有啊,现在越来越多了。这是研究者的话语权的问题。现在做中文研究的学者越来越多,而且中文现在越来越重要。20 年前,中文的数据就更少了,现在中文数据已经越来越多了。同时英语也是作为国际性的语言,大家更容易去用。这不是什么大的问题。
雷鸣:好,有同学问,NLP 和创业相结合的话,有什么比较值得做的东西?
李航:这是个很好的问题。人工智能还是要跟具体的业务结合起来。自然语言处理也一样。这是第一个要定。第二个要点我刚才其实也讲到了,你需要去判断,你做的 NLP 系统其性能能达到的上界,和你面对的需求所要求的性能的下届是否能对上?这是非常重要的一个判断。如果你预测未来技术发展到某个阶段,能使上界提高到满足或超过需求下界的水平,就可以考虑结合实际的应用了。这个场景是非常多的。有很多场景里,我们都可以使用 NLP,来把它做得更好。其实我整晚的课都在强调这两点:一个是应用驱动,或者说需求驱动;另一个就是这个上界下界的事情。
雷鸣:李航老师高屋建瓴。我对创业这块比较熟悉一点。我们现在能看到 NLP 相关的创业,大体说有两类。一类是指令式的,比如智能家居,你下达指令,让它开灯关灯;车载环境下也是指令类。车载环境真的不方便用手了,智能用嘴去下达指令,你可能会说,给我老妈拨个电话,或是把刚刚收到的微信信息读一下。另一类是 QA 类的,基本应用在客服上。这一块最近用得非常多。大企业会自己做客服系统,借助自身大量的客户积累,去实现问题和回答的匹配。当然有一些中小企业和传统企业,没有这个能力,所以有一些创业公司就切进去了。这种情况也不少。另外还有一类,就是利用 NLP 技术对以前积累的数据和知识进行分析和处理,比如文本构成的知识库,像卷宗、病历等等,用 Watson 这样的系统去分析它,尝试发掘一些规则的知识。
大体上来讲,大公司,比如华为,有人力、财力、物力,再加上有数据,同时还有应用场景,你去跟它抢这个市场难度很大。也不是说完全没有可能,但难度很大。而有一些行业,比如医疗,大公司也没有数据,都要去抢。这相应来讲还有一定机会。
再问一个问题。上节课上徐伟老师讲过,有一个调研,调研了一百位科学家,这些人中有一半人都认为,2050 年之前,强人工智能有超过 50% 的可能性会实现。当然你可能不同意这种说法。显然,通用人工智能应该能理解人类语言。这是不是意味着自然语言处理在接下来的三十年间也会有很大的发展?或者说,到最后,NLP 的问题会等价于通用人工智能的问题?
李航:有一个说法我比较认可,就是未来的 5 年、10 年,我们可以预测。20 年的话,基本上就不能预测了。2050 年的事情,真的谁都很难预测了。返回头说,十年前我们能预料到语音识别会达到现在的水平吗?十年前可能没有人能够预测得到。很多东西不好预测,预测未来是一个挺难的事情。尤其是现在技术突飞猛进,发展这么快,各种路数都出来,你知道哪边突破了?这都很难说。
还有,通用人工智能也没有一个准确的定义。在我看来,通用人工智能会在未来 10 年、20 年在一定程度上有突破,我也持这种观点。如果我们把通用人工智能定义为把语言、视觉、听觉等所有这些能力综合起来的一种能力,那么是完全有可能的。因为传统上认为人工智能太难了,所以大家把它分而治之,研究视觉的,研究听觉的,等等。现在如果说要通过类似深度学习的方法把这些串起来,这是可能的。比如说你把图像识别和语言处理放在一起做。其实人在成长过程中,学习最基本概念的时候,图像、语言等等也是同时来学习的。从这种意义上说,未来甚至不用那么长的时间,就能看到一些成功的案例了。现实中我们已经看到一些多模态的智能结合了。但是这还不能说是达到语言理解了。我觉得从这个意义上说,语言理解就更难了。
雷鸣:对。上一次我跟徐伟探讨时,也说到了通用人工智能的定义问题。我们当时有一个简单的小共识,认为它不是用解决什么问题来定义的,而是可能要看它的学习能力。比如说跟我们人类一样的通用人工智能,你让它学开车,人用一个月学会,它也可以用一个月学会;然后还是同样的一段程序,去让它学围棋,它和人类一样,花了三年时间,变成了业余几段。从学习能力来考察,可以认为它是实现了通用人工智能。
李航:对对,这个我同意。可以从学习能力来判断。
雷鸣:对,就是同一套程序,干啥都行。这是蛮有意思的探讨。
李航:对,我同意。
雷鸣:未来的事情确实真的都不好说,你刚才说返回头看,其实就算往回推一年,去年的 4 月份,谁也不知道 AlphaGo 能赢人啊。那时候大部分人认为还是赢不了的。
再问一个问题的,刚才咱们也提了关于知识的问题。我们知道,神经网络没有一个明确的存储,虽然它存起来了,但不知道存在哪里了。现在有一种网络,叫 memory network,里面加了内存。未来发展它的潜力会不会比较大?加了 memory 之后,包括推理、自然语言处理等方面的能力会不会有一个比较大的提升?还是说现在看也就是一个架构而已?
李航:刚才我说的神经符号处理,就是其中一部分,我觉得这个东西是非常非常重要的。时间关系我今天不能讲太多。我今年还会做一两个报告来讲这个事情。人的一个很重要的特点是能够把过去的事情都记忆起来,可以把记忆里面这些知识和事实的信息都能够串联起来。机器现在就没有这样的能力。AlphaGo 就没有一个记忆的能力。如果能够把知识、信息不断往里存储,根据需要检索,如果有了这个能力,对机器智能来说是非常大的提升。
雷鸣:我们现在看不到 neural network 里显式的记忆点在哪里,但是我们发现它是有隐式的记忆的。就像你刚才说的,问答在它的里面跑了几回,它就记住了,好像是记在什么地方了。那么是不是一定要显式的记忆才会有效?还是说只要网络足够的复杂,其实它也通过网络结构实现了记忆呢?
李航:是这样的,它在记语言的使用模式的时候,比如句法啊、回答问题的反式啊,等等,隐式记忆也许是可以的。但像知识啊、信息啊,这种事实性的东西,我们还是希望它是显式的,让人能够看到,能够检验。
雷鸣:有可解释性。
李航:对,它需要是可解释的。如果长期记忆这种机制成功的话,神经网络能够不断去记住新的东西,那它就会越来越强大。
我再多说一句,好莱坞电影里面会有人和机器人谈恋爱。那太遥远了。第一步,机器首先需要有自己的意识。意识有很多定义,一个最基本的定义,是说如果一个系统能对外界的变化产生反应,那就是一种意识。最简单的意识,比如说温度计,或者向日葵,都可以看做是有最基本的意识的。
雷鸣:这么说人工智能已经有意识了?
李航:从这个意义上说,是的。但人工智能没有自我意识。它不知道自己是谁。第一,有了意识;第二,如果你能有记忆,你就又进一步了;第三,如果你有自我意识,你就有可能以此为基础生发出情感。这样才可能和人类恋爱。所以说,目前的人工智能可以说已经有了最基本的意识了;如果它现在又有了记忆,它就能够把它整个的历史串起来了,我想这是整个智能机器在朝着自我意识的方向上又进化了一步。这件事是很激动人心的。
雷鸣:也有一点吓人(笑)。好,感谢李航老师的分享!
视频回放链接:http://www.iqiyi.com/l_19rrcceoer.html 课程介绍
“人工智能前沿与产业趋势” 课程由北京大学开设,并面向公众开放。课程由人工智能创新中心主任雷鸣老师主持,共 14 节,每节课邀请一位人工智能领域顶级专家和行业大咖作为主讲嘉宾,就人工智能和一个具体行业的结合深度探讨,分析相应技术的发展,如何影响产业,现状及未来趋势、对应挑战和与机遇。所有课程相关信息、通知都会在下方的公众号发布。
-
全面解析Tensor2Tensor系统
导语: Google Tensor2Tensor 系统是一套十分强大的深度学习系统,在多个任务上的表现非常抢眼。尤其在机器翻译问题上,单模型的表现就可以超过之前方法的集成模型。这一套系统的模型结构、训练和优化技巧等,可以被利用到公司的产品线上,直接转化成生产力。本文对 Tensor2Tensor 系统从模型到代码进行了全面的解析,期望能够给大家提供有用的信息。
第一章:概述
Tensor2Tensor(T2T)是 Google Brain Team 在 Github 上开源出来的一套基于 TensorFlow 的深度学习系统。该系统最初是希望完全使用 Attention 方法来建模序列到序列(Sequence-to-Sequence,Seq2Seq)的问题,对应于《Attention Is All You Need》这篇论文。该项工作有一个有意思的名字叫 “Transformer”。随着系统的不断扩展,T2T 支持的功能变得越来越多,目前可以建模的问题包括:图像分类,语言模型、情感分析、语音识别、文本摘要,机器翻译。T2T 在很多任务上的表现很好,并且模型收敛比较快,在 TF 平台上的工程化代码实现的也非常好,是一个十分值得使用和学习的系统。
如果是从工程应用的角度出发,想快速的上手使用 T2T 系统,只需要对模型有一些初步的了解,阅读一下 workthrough 文档,很快就能做模型训练和数据解码了。这就是该系统想要达到的目的,即降低深度学习模型的使用门槛。系统对数据处理、模型、超参、计算设备都进行了较高的封装,在使用的时候只需要给到数据路径、指定要使用的模型和超参、说明计算设备就可以将系统运行起来了。
如果想深入了解系统的实现细节,在该系统上做二次开发或是实现一些研究性的想法,那就需要花费一定的时间和精力来对模型和代码进行研究。T2T 是一个较复杂的系统,笔者近期对模型和代码实现进行了全面的学习,同时对涉及到序列到序列功能的代码进行了剥离和重构,投入了较多的时间成本。因笔者是做自然语言处理研究的,这篇文章里主要关注的是 Transformer 模型。写这篇文章一方面是总结和记录一下这个过程中的一些收获,另一方面是把自己对 T2T 的理解分享出来,希望能够提供一些有用的信息给同学们。
第二章:序列到序列任务与 Transformer 模型
2.1 序列到序列任务与 Encoder-Decoder 框架
序列到序列(Sequence-to-Sequence)是自然语言处理中的一个常见任务,主要用来做泛文本生成的任务,像机器翻译、文本摘要、歌词 / 故事生成、对话机器人等。最具有代表性的一个任务就是机器翻译(Machine Translation),将一种语言的序列映射到另一个语言的序列。例如,在汉 - 英机器翻译任务中,模型要将一个汉语句子(词序列)转化成一个英语句子(词序列)。
目前 Encoder-Decoder 框架是解决序列到序列问题的一个主流模型。模型使用 Encoder 对 source sequence 进行压缩表示,使用 Decoder 基于源端的压缩表示生成 target sequence。该结构的好处是可以实现两个 sequence 之间 end-to-end 方式的建模,模型中所有的参数变量统一到一个目标函数下进行训练,模型表现较好。图 1 展示了 Encoder-Decoder 模型的结构,从底向上是一个机器翻译的过程。
 图 1: 使用 Encoder-Decoder 模型建模序列到序列的问题
图 1: 使用 Encoder-Decoder 模型建模序列到序列的问题Encoder 和 Decoder 可以选用不同结构的 Neural Network,比如 RNN、CNN。RNN 的工作方式是对序列根据时间步,依次进行压缩表示。使用 RNN 的时候,一般会使用双向的 RNN 结构。具体方式是使用一个 RNN 对序列中的元素进行从左往右的压缩表示,另一个 RNN 对序列进行从右向左的压缩表示。两种表示被联合起来使用,作为最终序列的分布式表示。使用 CNN 结构的时候,一般使用多层的结构,来实现序列局部表示到全局表示的过程。使用 RNN 建模句子可以看做是一种时间序列的观点,使用 CNN 建模句子可以看做一种结构化的观点。使用 RNN 结构的序列到序列模型主要包括 RNNSearch、GNMT 等,使用 CNN 结构的序列到序列模型主要有 ConvS2S 等。
2.2 神经网络模型与语言距离依赖现象
Transformer 是一种建模序列的新方法,序列到序列的模型依然是沿用了上述经典的 Encoder-Decoder 结构,不同的是不再使用 RNN 或是 CNN 作为序列建模机制了,而是使用了 self-attention 机制。这种机制理论上的优势就是更容易捕获 “长距离依赖信息(long distance dependency)”。所谓的“长距离依赖信息” 可以这么来理解:1)一个词其实是一个可以表达多样性语义信息的符号(歧义问题)。2)一个词的语义确定,要依赖其所在的上下文环境。(根据上下文消岐)3)有的词可能需要一个范围较小的上下文环境就能确定其语义(短距离依赖现象),有的词可能需要一个范围较大的上下文环境才能确定其语义(长距离依赖现象)。
举个例子,看下面两句话:“山上有很多杜鹃,春天到了的时候,会漫山遍野的开放,非常美丽。” “山上有很多杜鹃,春天到了的时候,会漫山遍野的啼鸣,非常婉转。”在这两句话中,“杜鹃”分别指花(azalea)和鸟(cuckoo)。在机器翻译问题中,如果不看距其比较远的距离的词,很难将 “杜鹃” 这个词翻译正确。该例子是比较明显的一个例子,可以明显的看到词之间的远距离依赖关系。当然,绝大多数的词义在一个较小范围的上下文语义环境中就可以确定,像上述的例子在语言中占的比例会相对较小。我们期望的是模型既能够很好的学习到短距离的依赖知识,也能够学习到长距离依赖的知识。
那么,为什么 Transformer 中的 self-attention 理论上能够更好的捕获这种长短距离的依赖知识呢?我们直观的来看一下,基于 RNN、CNN、self-attention 的三种序列建模方法,任意两个词之间的交互距离上的区别。图 2 是一个使用双向 RNN 来对序列进行建模的方法。由于是对序列中的元素按顺序处理的,两个词之间的交互距离可以认为是他们之间的相对距离。W1 和 Wn 之间的交互距离是 n-1。带有门控(Gate)机制的 RNN 模型理论上可以对历史信息进行有选择的存储和遗忘,具有比纯 RNN 结构更好的表现,但是门控参数量一定的情况下,这种能力是一定的。随着句子的增长,相对距离的增大,存在明显的理论上限。
 图 2 使用双向 RNN 对序列进行建模
图 2 使用双向 RNN 对序列进行建模图 3 展示了使用多层 CNN 对序列进行建模的方法。第一层的 CNN 单元覆盖的语义环境范围较小,第二层覆盖的语义环境范围会变大,依次类推,越深层的 CNN 单元,覆盖的语义环境会越大。一个词首先会在底层 CNN 单元上与其近距离的词产生交互,然后在稍高层次的 CNN 单元上与其更远一些词产生交互。所以,多层的 CNN 结构体现的是一种从局部到全局的特征抽取过程。词之间的交互距离,与他们的相对距离成正比。距离较远的词只能在较高的 CNN 节点上相遇,才产生交互。这个过程可能会存在较多的信息丢失。
 图 3 使用多层 CNN 对序列进行建模
图 3 使用多层 CNN 对序列进行建模图 4 展示的是基于 self-attention 机制的序列建模方法。注意,为了使图展示的更清晰,少画了一些连接线,图中 “sentence” 层中的每个词和第一层 self-attention layer 中的节点都是全连接的关系,第一层 self-attention layer 和第二层 self-attention layer 之间的节点也都是全连接的关系。我们可以看到在这种建模方法中,任意两个词之间的交互距离都是 1,与词之间的相对距离不存在关系。这种方式下,每个词的语义的确定,都考虑了与整个句子中所有的词的关系。多层的 self-attention 机制,使得这种全局交互变的更加复杂,能够捕获到更多的信息。
 图 4 使用 self-attention 对序列进行建模
图 4 使用 self-attention 对序列进行建模综上,self-attention 机制在建模序列问题时,能够捕获长距离依赖知识,具有更好的理论基础。
2.3 self-attention 机制的形式化表达
上面小节介绍了 self-attention 机制的好处,本小结来介绍一下 self-attention 机制的的数学形式化表达。首先,从 attention 机制讲起。可以将 attention 机制看做一种 query 机制,即用一个 query 来检索一个 memory 区域。我们将 query 表示为 key_q,memory 是一个键值对集合(a set of key-value pairs),共有 M 项,其中的第 i 项我们表示为
2.4 “Attention is All You Need”
《Attention Is All You Need》这篇文章,描述了一个基于 self-attention 的序列到序列的模型,即 “Transformer”。该模型将 WMT2014 英 - 德翻译任务的 BLEU 值推到了新高,在英 - 法翻译任务上,接近于之前报出的最好成绩,而这仅仅是 Transformer 单模型的表现。之前报出的最好成绩都是基于集成方法的,需要训练多个模型,最后做集成。同时该模型也被用在英语的成分句法分析任务上,表现也基本接近于之前报出的最好模型成绩。该模型的收敛速度也非常的快,在英 - 法 3600 万句对的训练集上,只需要 8 卡并行 3.5 天就可以收敛。
该模型的表现的如此好的原因,其实不仅仅是一个 self-attention 机制导致的,实际上 Transformer 模型中使用了非常多有效的策略来使得模型对数据的拟合能力更强,收敛速度更快。整个 Transformer 的模型是一套解决方案,而不仅仅是对序列建模机制的改进。下面我们对其进行一一讲解。
2.4.1 Self-attention 机制的变种
首先,还是来讲一下 Transformer 中的 self-attention 机制。上面讲到了 self-attention 的基本形式,但是 Transformer 里面的 self-attention 机制是一种新的变种,体现在两点,一方面是加了一个缩放因子(scaling factor),另一方面是引入了多头机制(multi-head attention)。
缩放因子体现在 Attention 的计算公式中多了一个向量的维度作为分母,目的是想避免维度过大导致的点乘结果过大,进入 softmax 函数的饱和域,引起梯度过小。Transformer 中的 self-attention 计算公式如下:

多头机制是指,引入多组的参数矩阵来分别对 Q、K、V 进行线性变换求 self-attention 的结果,然后将所有的结果拼接起来作为最后的 self-attention 输出。这样描述可能不太好理解,一看公式和示意图就会明白了,如下:

 图 5 单头和多头的 Attention 结构
图 5 单头和多头的 Attention 结构这种方式使得模型具有多套比较独立的 attention 参数,理论上可以增强模型的能力。
2.4.2 位置编码(Positional Encoding)
self-attention 机制建模序列的方式,既不是 RNN 的时序观点,也不是 CNN 的结构化观点,而是一种词袋(bag of words)的观点。进一步阐述的话,应该说该机制视一个序列为扁平的结构,因为不论看上去距离多远的词,在 self-attention 机制中都为 1。这样的建模方式,实际上会丢失词之间的相对距离关系。举个例子就是,“牛 吃了 草”、“草 吃了 牛”,“吃了 牛 草” 三个句子建模出来的每个词对应的表示,会是一致的。
为了缓解这个问题,Transformer 中将词在句子中所处的位置映射成 vector,补充到其 embedding 中去。该思路并不是第一次被提出,CNN 模型其实也存在同样的难以建模相对位置(时序信息)的缺陷,Facebook 提出了位置编码的方法。一种直接的方式是,直接对绝对位置信息建模到 embedding 里面,即将词 Wi 的 i 映射成一个向量,加到其 embedding 中去。这种方式的缺点是只能建模有限长度的序列。Transformer 文章中提出了一种非常新颖的时序信息建模方式,就是利用三角函数的周期性,来建模词之间的相对位置关系。具体的方式是将绝对位置作为三角函数中的变量做计算,具体公式如下:

该公式的设计非常先验,尤其是分母部分,不太好解释。从笔者个人的观点来看,一方面三角函数有很好的周期性,也就是隔一定的距离,因变量的值会重复出现,这种特性可以用来建模相对距离;另一方面,三角函数的值域是 [-1,1],可以很好的提供 embedding 元素的值。
2.4.3 多层结构
Transformer 中的多层结构非常强大,使用了之前已经被验证过的很多有效的方法,包括:residual connection、layer normalization,另外还有 self-attention 层与 Feed Forward 层的堆叠使用,也是非常值得参考的结构。图 6 展示了 Transformer 的 Encoder 和 Decoder 一层的结构。
 图 6 Transformer 模型结构
图 6 Transformer 模型结构图 6 中,左侧的 Nx 代表一层的 Encoder,这一层中包含了两个子层(sub-layer),第一个子层是多头的 self-attention layer,第二个子层是一个 Feed Forward 层。每个子层的输入和输出都存在着 residual connection,这种方式理论上可以很好的回传梯度。Layer Normalization 的使用可以加快模型的收敛速度。self-attention 子层的计算,我们前面用了不少的篇幅讲过了,这里就不再赘述了。Feed Forward 子层实现中有两次线性变换,一次 Relu 非线性激活,具体计算公式如下:

文章的附页中将这种计算方式也看做是一种 attention 的变种形式。
图 6 中,右侧是 Decoder 中一层的结构,这一层中存在三个子层结构,第一层是 self-attention layer 用来建模已经生成的目标端句子。在训练的过程中,需要一个 mask 矩阵来控制每次 self-attention 计算的时候,只计算到前 t-1 个词,具体的实现方式,我们会在后面讲代码实现的时候进行说明。第二个子层是 Encoder 和 Decoder 之间的 attention 机制,也就是去源语言中找相关的语义信息,这部分的计算与其他序列到序列的注意力计算一致,在 Transformer 中使用了 dot-product 的方式。第三个子层是 Feed Forward 层,与 Encoder 中的子层完全一致。每个子层也都存在着 residual connection 和 layer normalization 操作,以加快模型收敛。
Transformer 中的这种多层 - 多子层的机制,可以使得模型的复杂度和可训练程度都变高,达到非常强的效果,值得我们借鉴。
2.4.4 优化方法与正则策略
模型的训练采用了 Adam 方法,文章提出了一种叫 warm up 的学习率调节方法,如公式所示:

公式比较先验,看上去比较复杂,其实逻辑表达起来比较清楚,需要预先设置一个 warmup_steps 超参。当训练步数 step_num 小于该值时,以括号中的第二项公式决定学习率,该公式实际是 step_num 变量的斜率为正的线性函数。当训练步数 step_num 大于 warm_steps 时,以括号中的第一项决定学习率,该公式就成了一个指数为负数的幂函数。所以整体来看,学习率呈先上升后下降的趋势,有利于模型的快速收敛。
模型中也采用了两项比较重要的正则化方法,一个就是常用的 dropout 方法,用在每个子层的后面和 attention 的计算中。另一个就是 label smoothing 方法,也就是训练的时候,计算交叉熵的时候,不再是 one-hot 的标准答案了,而是每个 0 值处也填充上一个非 0 的极小值。这样可以增强模型的鲁棒性,提升模型的 BLEU 值。这个思路其实也是一定程度在解决训练和解码过程中存在的 exposure bias 的问题。
2.4.5 本章小结
Transformer 系统的强大表现,不仅仅是 self-attention 机制,还需要上述的一系列配合使用的策略。设计该系统的研究者对深度学习模型和优化算法有着非常深刻的认识和敏锐的感觉,很多地方值得我们借鉴学习。Transformer 的代码实现工程化比较好,但是也存在一些地方不方便阅读和理解,后面的章节中会对 Transformer 的代码实现进行详细讲解,将整体结构讲清楚,把其中的疑难模块点出来。
第三章:Tensor2Tensor 系统实现深度解析
Tensor2Tensor 的系统存在一些特点,导致使用和理解的时候可能会存在一些需要时间来思考和消化的地方,在此根据个人的理解,写出一些自己曾经花费时间的地方。
3.1 使用篇
Tensor2Tensor 的使用是比较方便的,对于系统中可以支持的问题,直接给系统设置好下面的信息就可以运行了:数据,问题 (problem),模型,超参集合,运行设备。这里的实现其实是采用了设计模型中的工厂模式,即给定一个问题名字,返回给相应的处理类;给定一个超参名,返回一套超参的对象。实现这种方式的一个重点文件是 utils/registry.py。在系统启动的时候,所有的问题和超参都会在 registry 中注册,保存到_MODELS,_HPAPAMS,_RANGED_HPARAMS 中等待调用。
在此主要以序列到序列的系统使用和实现为主线进行讲解。系统的运行分三个阶段:数据处理,训练,解码。对应着三个入口:t2t-datagen,t2t-trainer,t2t-decoder。
数据处理的过程包括:
1.(下载)读取训练和开发数据。如果需要使用自己的数据的话,可以在问题中指定。
2.(读取)构造词汇表。可以使用自己预先构造好的词汇表。系统也提供构建 BPE 词汇表的方法。注意,这里有个实现细节是系统在抽取 BPE 词汇表的时候,有个参数,默认并非使用全量的数据。通过多次迭代尝试,得到最接近预设词汇表规模的一个词汇表。在大数据量的时候,这个迭代过程会非常慢。
3. 使用词汇表将单词映射成 id,每个句子后会加 EOS_ID,每个平行句对被构造成一个 dict 对象 ({‘inputs’:value,‘targets’:value}),将所有对象序列化,写入到文件中,供后面训练和评价使用。
模型训练的过程的过程主要通过高级的 Tensorflow API 来管理,只是需要指定数据、问题名、模型名、超参名、设备信息就可以运行了。比较关键的一个文件是 utils/trainer_lib.py 文件,在这个文件中,构建 Experiment、Estimator、Monitor 等来控制训练流程。使用者主要需要设置的就是训练过程的一些参数,比如训练最大迭代次数,模型评估的频率,模型评估的指标等。超参可以直接使用系统已有的参数集,也可以通过字符串的形式向内传参。简单的任务不太需要动超参,因为系统中的超参集合基本上都是经过实验效果验证的。需要注意的就是 batch_size 过大的时候,可能会导致显存不足,导致程序错误。一般是使用 continuous_train_and_eval 模式,使模型的训练和评估间隔进行,随时可以监控模型的表现。
解码的过程,可以提供整体文件、也可以是基于 Dataset 的,同时系统也提供 server 的方式,可以提供在线的服务,并没有什么特别好讲的。
3.2 深度掌握篇
3.2.1 Tensor2Tensor 系统实现的特点
下面列出了要深度掌握 Tensor2Tensor 系统时,可能因为其实现特点,会遇到的一些问题:
1. 系统支持多任务,任务混杂,导致代码结构比较复杂。在实现的时候,要考虑到整体的结构,所以会存在各种封装、继承、多态的实现。可能你只想用其中的一个功能,理解该功能对应的代码,但是却需要排除掉大量的不相关的代码。
2. 系统基于 Tensorflow 封装较高的 API。使用了 Tensorflow 中比较高的 API 来管理模型的训练和预测,Experiment,Monitor,Estimator,Dataset 对象的使用隐藏了比较多的控制流程,对于侧重应用的用户来说,可能是是好事情,设一设参数就能跑。但是对于想了解更多的开发人员来说,TF 该部分的文档实在很少,说的也不清楚,很多时候需要去阅读源代码才能知道实验到底是不是按照自己预期的进行的。这种方式也不太方便找 bug 和调试。
3. 某些方法调用比较深。原因应该还是出于整体结构和扩展性的考虑。这导致了实现一点很小功能的方法 A,需要再调一个其他方法 B,B 再去调用方法 C,实际上每个方法中就几行代码,甚至有的方法就是空操作。
4. 多层继承和多态也降低了代码的可读性。追溯一个类的某个方法的时候,需要看到其父类的父类的父类。。。这些父类和子类之间的方法又存在着调来调去的关系,同名方法又存在着覆盖的关系,所以要花一些时间来确定当前的方法名到底是调用的的哪个类中的方法。
5. 要求开发者有模型层面的理解和与代码实现的挂钩。肯定是要提高对模型逻辑的理解,但在读代码的过程中,会遇到两种问题:第一个,代码实现的是论文中的功能,但不是论文中的原始公式,可能要做变形以规避溢出的问题,或是实现更高的效率;第二个,某些代码实现与其论文中的表述存在不一致的情况。
3.2.2 总体逻辑模块
总体来说,对 T2T 系统的代码逻辑划分如下,共包括三个大的模块:
- 问题定义和数据管理的模块。该模块用来定义问题和处理数据,比如定义一个翻译的问题,里面定义抽词汇表和构造训练样本的方法。
- 模型定义和计算图构建的模块。该模块用来定义模型属性和计算图结构。
- 实验流程控制与并行化模块。该模块用于实验流程控制,设置可用计算设备,提供模型并行化运行方法。
 图 7 Tensor2Tensor 主要逻辑模块
图 7 Tensor2Tensor 主要逻辑模块这里不会对代码做追踪式的分析,会分条的讲解一些阅读 Tensor2Tensor 系统代码时可能遇到的问题,点出一些重要的功能所在的位置和实现逻辑。
- 工厂模式。系统使用工厂模式管理问题、模型、超参、模态等模块的方法。前面在使用篇讲到了 registry.py 这个比较关键的文件,是系统总体管理和调度模块的一个核心文件。如果要在系统中增加新的问题、模型、超参、模态等,也都需要通过在类前加装饰器的方式来注册到 registry 中,否则系统找不到新加的模块。
- ** 问题类 (problem)。**data_generators/problem.py 中的 class Problem 是后面所有 problem 的基类。之前说到系统中的类之间的多层继承关系导致代码读起来比较麻烦,举个例子来说,一个翻译问题继承路线是这样的:Problem»Text2TextProblem»TranslateProblem»TranslateEndeWmtBpe32k» TranslateEndeWmt32k,中间各种的方法和变量覆盖,父类和子类之间方法的穿插调用,导致一些阅读困难。总的来说,一个序列到序列的问题应该包括以下信息和方法:数据文件信息,词汇表文件名、类型、大小,构造词汇表的方法,序列化训练数据和开发数据的方法,读取数据文件为 model(estimator)构造输入流 input_fn 的方法,设定问题评估 metric 的方法。可以总结来说,问题的属性定义、训练和评价样本的构造、数据的处理和读取,都由 problem 这个体系里面的类和方法来提供。
- 词汇表对象 (TextEncoder)。系统中有多种多样的词汇表(TextEncoder)对象,可以支持字母(character),子词(subword/bpe),词汇(token)等多重方式。TextEncoder 主要功能就是构建词汇表、实现符号到 id 的映射。T2T 里有构造 bpe 词汇表的方法,没有 word piece 词汇表的构造方法,也可以看出 T2T 研究团队和 GNMT 研究团队的区分。两个团队一直在交替的更新机器翻译任务的最高成绩。构建 BPE 词汇表的具体实现在 SubwordTextEncoder 中的 build_to_target_size()方法,该方法不是之前 Sennrich 使用迭代次数来控制词汇表大小的方式,而是使用二分查找的方式,通过搜索最优的 minimum token count 值来逼近预先设置的词汇表的大小。
- T2TModel 类。utils/t2t_model.py 中的 class T2TModel 是模型功能的基类,该类继承自 layer,Transformer 类便继承于此类。T2TModel 类中定义了模型的计算图结构,即给定 feature 后,模型是怎么根据 feature 进行图计算,得到 logit,loss,然后根据 loss 求梯度,调用 optimizer 进行梯度回传,进行参数更新的。构建计算图的目的是最终要构建 tf.estimator.EstimatorSpec()对象。可以理解为,所有的模型图计算过程都在该对象中被表达了。T2TModel 可以返回三种 EstimatorSpec 对象,分别用于训练、评价和解码。训练的过程可以支持数据并行,具体的实现是同时在多个数据片上激活计算图,得到的 loss 做平均,这是一种同步并行训练的方式。T2TModel 中也提供了供解码的方法。
- Transformer 类。models/transformer.py 中的 class Transformer 继承自 class T2TModel,为其父类构建图的时候,提供各种支持的方法,encode 方法可以使用 Encoder 结构对源端进行压缩表示,decode 方法使用 Decoder 结构对目标端进行生成。同时,transformer.py 中有多套参数供选择。模型中 feed-forward 子层的实现也在该文件中 (transformer_ffn_layer)。
- 数据并行类。devices.py 和 expert_utils.py 配合使用,主要功能是根据用户给定的并行设备参数,列出可以使用的设备名,然后给定一个能够调用这些设备,并行执行方法的方法。
- 实验流程控制。实验流程控制使用的是 Tensorflow 的高级 API 对象,主要包括 Experiment 对象、Estimator 对象、Dataset 对象。对这三个对象,我们可以这么理解:a) Experiment 是一次运行的实验,用来控制实验流程,输送数据到模型。b) Estimator 是具体的模型对象,可以包括训练、评估、解码三个功能。c) Dataset 为运行的实验过程读数据文件提供数据流。
- Experiment 对象。我们来看下图中 Experiment 初始化所需的形参就能更好的理解 “实验” 这个概念了。Experiment 对象中需要迭代中的各种 step 参数,需要一个 Estimator 对象,两个输入流函数(input)。Experiment 对象在运行中,将数据给到 Estimator 对象,然后控制训练和迭代流程。
 图 8 Experiment 对象的部分形参
图 8 Experiment 对象的部分形参9.Estimator 对象。可以理解为模型对象,可以通过 Estimator 执行模型的训练、评估、解码。Estimator 对象最重要的一个形参是 model_fn,也就是具体执行训练、评估、解码的函数入口。三个入口分别对应着三个 EstimatorSpec 对象,如图 9,10 所示。
 图 9 Estimator 中最重要的形参是 model_fn
图 9 Estimator 中最重要的形参是 model_fn 图 10 Estimator 中的三种 model_fn,实现三种功能
图 10 Estimator 中的三种 model_fn,实现三种功能从图 10 可以看出,用于训练的 EstimatorSpec 对象需要描述计算图中 feature 和(loss,train_op)之间的关系;用于评估的 EstimatorSpec 对象需要描述计算图中 feature 和(loss,eval_metrics_ops)之间的关系;用于评估的 EstimatorSpec 对象需要描述 features 和 predictions 之间的关系。
- Dataset 对象。该对象是读文件,构造训练和评估的数据流。训练和评估对应着两种不同的数据输入流,如图 11 所示。
 图 11 Dataset 对象提供数据流
图 11 Dataset 对象提供数据流\11. Positional encoding 的实现。论文中的实现和代码中的实现存在公式变形和不一致的情况,可能会导致困惑,故在此指出。论文中 Positional encoding 中三角函数的参数部分公式如下:

代码中的实现需要对该公式做变形,以规避数值溢出的风险,公式变形过程如下:

还需要指出的是,论文中根据维度下标的奇偶性来交替使用 sin 和 cos 函数的说法,在代码中并不是这样实现的,而是前一半的维度使用 sin 函数,后一半的维度使用 cos 函数,并没有考虑奇偶性
12. 以 token 数量作为 batch size。这种方式比起以句子个数作为 batch size 的方式来,能到 batch 占显存的空间更加平均,不会导致因为训练数据导致的显存占用忽上忽下,造成显存空间不够用,导致程序崩溃。
\13. 如何做 mask。由于模型是以 batch 为单位进行训练的,batch 的句长以其中最长的那个句子为准,其他句子要做 padding。padding 项在计算的过程中如果不处理的话,会引入噪音,所以就需要 mask,来使 padding 项不对计算起作用。mask 在 attention 机制中的实现非常简单,就是在 softmax 之前,把 padding 位置元素加一个极大的负数,强制其 softmax 后的概率结果为 0。举个例子,[1,1,1] 经过 softmax 计算后结果约为 [0.33,0.33,0.33],[1,1,-1e9] softmax 的计算结果约为 [0.5, 0.5,0]。这样就相当于 mask 掉了数组中的第三项元素。在对 target sequence 进行建模的时候,需要保证每次只 attention 到前 t-1 个单词,这个地方也需要 mask,整体的 mask 是一个上三角矩阵,非 0 元素值为一个极大的负值。
\14. 基于 batch 的解码。解码的时候,如果是基于文件的,那么就会将句子组成 batch 来并行解码。这里有个小 trick,就是先对句子进行排序,然后从长的句子开始组 batch,翻译,再把句子恢复成原先的顺序返回。这种方式可以很好的检测到显存不足的错误,因为解句子最长的一个 batch 的时候,显存都是够得,那其他的 batch 也不存在问题。
总结
本文对 Google 的 Tensor2Tensor 系统进行了深度的解读,涉及到了比较多的方面,笔者也还需要对其进行更加深入的学习和研究,希望能够与对该模型以及 DL for NLP 技术感兴趣的同学们一起交流,共同进步!
问答
docker 和 docker-compose 有什么不同?
相关阅读
此文已由作者授权腾讯云 + 社区发布,原文链接:https://cloud.tencent.com/developer/article/1116709?fromSource=waitui
欢迎大家前往腾讯云 + 社区或关注云加社区微信公众号(QcloudCommunity),第一时间获取更多海量技术实践干货哦~
海量技术实践经验,尽在云加社区! https://cloud.tencent.com/developer?fromSource=waitui
-
使用pytorch识别mnist
转载自:https://github.com/zergtant/pytorch-handbook/blob/master/chapter3/3.2-mnist.ipynb
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms torch.__version__
-
pytorch中cnn的使用
转载自:https://github.com/zergtant/pytorch-handbook/blob/master/chapter2/2.4-cnn.ipynb
import torch torch.__version__
-
Word2Vec Tutorial part2
转载自:http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
Word2Vec Tutorial Part 2 - Negative Sampling
11 Jan 2017
In part 2 of the word2vec tutorial (here’s part 1), I’ll cover a few additional modifications to the basic skip-gram model which are important for actually making it feasible to train.
When you read the tutorial on the skip-gram model for Word2Vec, you may have noticed something–it’s a huge neural network!
In the example I gave, we had word vectors with 300 components, and a vocabulary of 10,000 words. Recall that the neural network had two weight matrices–a hidden layer and output layer. Both of these layers would have a weight matrix with 300 x 10,000 = 3 million weights each!
Running gradient descent on a neural network that large is going to be slow. And to make matters worse, you need a huge amount of training data in order to tune that many weights and avoid over-fitting. millions of weights times billions of training samples means that training this model is going to be a beast.
The authors of Word2Vec addressed these issues in their second paper.
There are three innovations in this second paper:
- Treating common word pairs or phrases as single “words” in their model.
- Subsampling frequent words to decrease the number of training examples.
- Modifying the optimization objective with a technique they called “Negative Sampling”, which causes each training sample to update only a small percentage of the model’s weights.
It’s worth noting that subsampling frequent words and applying Negative Sampling not only reduced the compute burden of the training process, but also improved the quality of their resulting word vectors as well.
Word Pairs and “Phrases”
The authors pointed out that a word pair like “Boston Globe” (a newspaper) has a much different meaning than the individual words “Boston” and “Globe”. So it makes sense to treat “Boston Globe”, wherever it occurs in the text, as a single word with its own word vector representation.
You can see the results in their published model, which was trained on 100 billion words from a Google News dataset. The addition of phrases to the model swelled the vocabulary size to 3 million words!
If you’re interested in their resulting vocabulary, I poked around it a bit and published a post on it here. You can also just browse their vocabulary here.
Phrase detection is covered in the “Learning Phrases” section of their paper. They shared their implementation in word2phrase.c–I’ve shared a commented (but otherwise unaltered) copy of this code here.
I don’t think their phrase detection approach is a key contribution of their paper, but I’ll share a little about it anyway since it’s pretty straightforward.
Each pass of their tool only looks at combinations of 2 words, but you can run it multiple times to get longer phrases. So, the first pass will pick up the phrase “New_York”, and then running it again will pick up “New_York_City” as a combination of “New_York” and “City”.
The tool counts the number of times each combination of two words appears in the training text, and then these counts are used in an equation to determine which word combinations to turn into phrases. The equation is designed to make phrases out of words which occur together often relative to the number of individual occurrences. It also favors phrases made of infrequent words in order to avoid making phrases out of common words like “and the” or “this is”.
You can see more details about their equation in my code comments here.
One thought I had for an alternate phrase recognition strategy would be to use the titles of all Wikipedia articles as your vocabulary.
Subsampling Frequent Words
In part 1 of this tutorial, I showed how training samples were created from the source text, but I’ll repeat it here. The below example shows some of the training samples (word pairs) we would take from the sentence “The quick brown fox jumps over the lazy dog.” I’ve used a small window size of 2 just for the example. The word highlighted in blue is the input word.
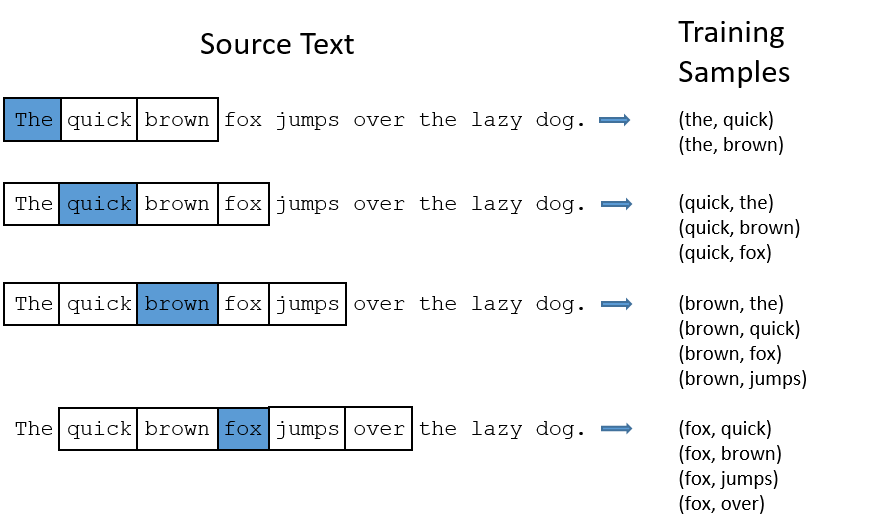
There are two “problems” with common words like “the”:
- When looking at word pairs, (“fox”, “the”) doesn’t tell us much about the meaning of “fox”. “the” appears in the context of pretty much every word.
- We will have many more samples of (“the”, …) than we need to learn a good vector for “the”.
Word2Vec implements a “subsampling” scheme to address this. For each word we encounter in our training text, there is a chance that we will effectively delete it from the text. The probability that we cut the word is related to the word’s frequency.
If we have a window size of 10, and we remove a specific instance of “the” from our text:
- As we train on the remaining words, “the” will not appear in any of their context windows.
- We’ll have 10 fewer training samples where “the” is the input word.
Note how these two effects help address the two problems stated above.
Sampling rate
The word2vec C code implements an equation for calculating a probability with which to keep a given word in the vocabulary.
wiwi is the word, z(wi)z(wi) is the fraction of the total words in the corpus that are that word. For example, if the word “peanut” occurs 1,000 times in a 1 billion word corpus, then z(‘peanut’) = 1E-6.
There is also a parameter in the code named ‘sample’ which controls how much subsampling occurs, and the default value is 0.001. Smaller values of ‘sample’ mean words are less likely to be kept.
P(wi)P(wi) is the probability of keeping the word:
P(wi)=(z(wi)0.001−−−−−√+1)⋅0.001z(wi)P(wi)=(z(wi)0.001+1)⋅0.001z(wi)
You can plot this quickly in Google to see the shape.
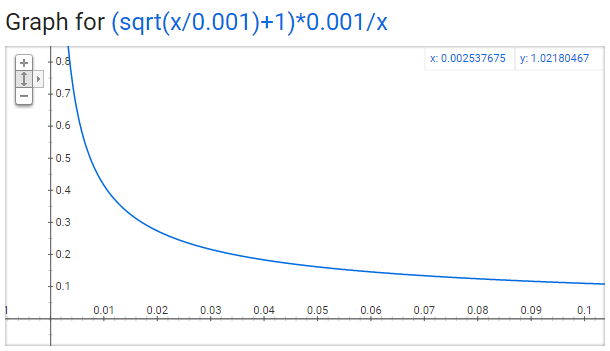
No single word should be a very large percentage of the corpus, so we want to look at pretty small values on the x-axis.
Here are some interesting points in this function (again this is using the default sample value of 0.001).
-
P(wi)=1.0P(wi)=1.0
(100% chance of being kept) when
z(wi)<=0.0026z(wi)<=0.0026
.
- This means that only words which represent more than 0.26% of the total words will be subsampled.
-
P(wi)=0.5P(wi)=0.5 (50% chance of being kept) when z(wi)=0.00746z(wi)=0.00746.
-
P(wi)=0.033P(wi)=0.033
(3.3% chance of being kept) when
z(wi)=1.0z(wi)=1.0
.
- That is, if the corpus consisted entirely of word wiwi, which of course is ridiculous.
You may notice that the paper defines this function a little differently than what’s implemented in the C code, but I figure the C implementation is the more authoritative version.
Negative Sampling
Training a neural network means taking a training example and adjusting all of the neuron weights slightly so that it predicts that training sample more accurately. In other words, each training sample will tweak all of the weights in the neural network.
As we discussed above, the size of our word vocabulary means that our skip-gram neural network has a tremendous number of weights, all of which would be updated slightly by every one of our billions of training samples!
Negative sampling addresses this by having each training sample only modify a small percentage of the weights, rather than all of them. Here’s how it works.
When training the network on the word pair (“fox”, “quick”), recall that the “label” or “correct output” of the network is a one-hot vector. That is, for the output neuron corresponding to “quick” to output a 1, and for all of the other thousands of output neurons to output a 0.
With negative sampling, we are instead going to randomly select just a small number of “negative” words (let’s say 5) to update the weights for. (In this context, a “negative” word is one for which we want the network to output a 0 for). We will also still update the weights for our “positive” word (which is the word “quick” in our current example).
The paper says that selecting 5-20 words works well for smaller datasets, and you can get away with only 2-5 words for large datasets.
Recall that the output layer of our model has a weight matrix that’s 300 x 10,000. So we will just be updating the weights for our positive word (“quick”), plus the weights for 5 other words that we want to output 0. That’s a total of 6 output neurons, and 1,800 weight values total. That’s only 0.06% of the 3M weights in the output layer!
In the hidden layer, only the weights for the input word are updated (this is true whether you’re using Negative Sampling or not).
Selecting Negative Samples
The “negative samples” (that is, the 5 output words that we’ll train to output 0) are selected using a “unigram distribution”, where more frequent words are more likely to be selected as negative samples.
For instance, suppose you had your entire training corpus as a list of words, and you chose your 5 negative samples by picking randomly from the list. In this case, the probability for picking the word “couch” would be equal to the number of times “couch” appears in the corpus, divided the total number of word occus in the corpus. This is expressed by the following equation:
P(wi)=f(wi)∑nj=0(f(wj))P(wi)=f(wi)∑j=0n(f(wj))
The authors state in their paper that they tried a number of variations on this equation, and the one which performed best was to raise the word counts to the 3/4 power:
P(wi)=f(wi)3/4∑nj=0(f(wj)3/4)P(wi)=f(wi)3/4∑j=0n(f(wj)3/4)
If you play with some sample values, you’ll find that, compared to the simpler equation, this one has the tendency to increase the probability for less frequent words and decrease the probability for more frequent words.
The way this selection is implemented in the C code is interesting. They have a large array with 100M elements (which they refer to as the unigram table). They fill this table with the index of each word in the vocabulary multiple times, and the number of times a word’s index appears in the table is given by P(wi)P(wi) * table_size. Then, to actually select a negative sample, you just generate a random integer between 0 and 100M, and use the word at that index in the table. Since the higher probability words occur more times in the table, you’re more likely to pick those.
Other Resources
For the most detailed and accurate explanation of word2vec, you should check out the C code. I’ve published an extensively commented (but otherwise unaltered) version of the code here.
Also, did you know that the word2vec model can also be applied to non-text data for recommender systems and ad targeting? Instead of learning vectors from a sequence of words, you can learn vectors from a sequence of user actions. Read more about this in my new post here.
Finally, I’ve also created a post with links to and descriptions of other word2vec tutorials, papers, and implementations.
Cite
McCormick, C. (2017, January 11). Word2Vec Tutorial Part 2 - Negative Sampling. Retrieved from http://www.mccormickml.com